FOLIO Cross-Application Data Sync Solution
- Raman Auramau
Summary
It is an architectural document describing the context, analysis and recommended approach for addressing the FOLIO cross-application data consistency problem.
Problem Statement
Data consistency refers to whether the same data kept at different places do or do not match. Being a distributed micro-services-based platform, FOLIO is a number of separate modules with their own data schemas and storage. So, FOLIO follows the principle to keep each module’s persistent data private to that module and accessible only via its API. A module’s transactions only involve its database.
With that, this approach has some challenges, among them -
- Updating and / or deleting copies of data in different modules,
- Implementing business transactions that span multiple services,
- Implementing queries that join data that is in multiple databases.
The problem of cross-application data synchronization belongs to the first of the listed problems. It can be briefly described as follows:
- one application owns some data - let's call it original data,
- one or several fields of this data are duplicated in the data of other application(s) (for various purposes - search, filtering, sorting, connectivity, etc.) - let's call them duplicate data,
- when the original data is changed or deleted, the duplicate data remains in an inconsistent state.
To date, the working group has identified about 30 use cases from different applications and parts of FOLIO that relate to this data synchronization problem. All of these cases can be logically grouped into a few categories. Categories and some related definitions are listed below.
# | Category | Definition |
a | Copies of data to be updated | When data in one app is updated, any other app that has a copy of that data it should also be updated |
b | Notify use of data in other apps | When one app owns some data and another app is making use of that data, the owning app should be aware, and able to display to the user, that information |
c | Notify on deletion | When some data is deleted from an app, other apps depending on that data should be notified / able to react appropriately |
d | Block on deletion | When one app owns some data and other app is making use of that data, the owning app should be unable to delete the data |
e | Notify on data update | When some data is updated in an app, other apps depending on that data should be notified / able to react appropriately |
It is important to note that categories a, c and e can be considered as quite close to each other as
- deletion of the original data (category c) is an update to the data
- reacting appropriately on a data update (category e) could include updating a copy of the data (category a)
Assumption: This proposal addresses use cases in categories a. Copies of data to be updated, c. Notify on deletion and e. Notify on data update; it does not address use cases in categories b. Notify use of data in other apps and d. Block on deletion
Requirements
The main functional requirement for this proposal can be formulated in the form of use cases based on the categories mentioned above: When some data is updated in an application or deleted from an application, other applications depending on that data should be notified and be able to react appropriately.
Non-functional requirements include the following (please, refer to Application Architecture Guide - Quality Attributes for more details and examples of non-functional requirements):
- performance - information about all data changes should become available to other applications in no more than 5 minutes,
- reliability - information about all data changes must be guaranteed to be available to other applications depending on that data within the so called longevity window which must be at least 48 hours,
- reliability - after the restoration of normal operation of a particular application after its temporary unavailability for any reason (planned downtime or unplanned outage), this application must be able to receive all notifications generated during the time of its unavailability within the longevity window,
- conceptual integrity - low coupling between applications and modules is expected,
- the solution must provide the ability to deliver and consume events in the appropriate order.
Target solution
The main concepts and details of the proposed solution are described below.
Basic solution concepts
This solution is based on several important concepts and patterns, including:
- Eventual Consistency pattern - very briefly, eventual consistency means that if the system is functioning and we wait long enough after any given set of inputs, we will eventually be able to know what the state of the database is, and so any further reads will be consistent with our expectations.
- Domain Event pattern - according to this pattern a service, or a module, or an application emits so called domain events when domain objects/data changed, and publishes these domain events to a notification channel so that they can be consumed by other services.
- Single Source of Truth - referring to the Problem Statement described earlier in this document, the challenge of cross-application data synchronization itself occurs when one application owns some original data, while the other application(s) has a copy of one or several fields of this data. Therefore, in the scope of this document, the term Single Source of Truth is used to refer to the application that owns the original data. It's also assumed that identification an application owning original domain data (i.e. Single Source of Truth) is possible.
High-level design
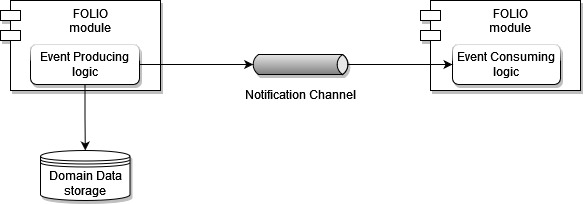
At the top level, this solution includes the following logical parts:
- Event Producer,
- Notification Channel, and
- Event Consumer.
The Event Producer is responsible for ensuring that whenever a domain object is changed (including its creation, modification, and deletion), a specific domain event is generated and posted to the Notification Channel. Note that the Event Producer does not send domain events to a particular consumer; it just publishes events to the Notification Channel where they can be consumed by any consumers. Any FOLIO module that is a Single Source of Truth of some domain data can act as the Event Producer.
In turn, the Event Consumer is responsible for reading the domain event from the Notification Channel and for the subsequent processing of this event in accordance with its own needs. By processing a domain event in accordance with own needs, one means any logic that is implemented in the Event Consumer - it can be updating its data or deleting some records, as well as an empty action. Thus, any FOLIO module that is a Single Source of Truth of some domain data can act as the Event Producer. Thus, any FOLIO module that needs to be notified on some domain data changes should act as the Event Consumer.
The Notification Channel operates between the Event Producer and the Event Consumer. Its main purpose is to ensure event delivery and the ability to store all published events for a given period of time. Apache Kafka tool is proposed for use as the Notification Channel in this solution, since, on the one hand, it has the necessary properties, and on the other hand, it is a tool that is used on the FOLIO platform.
The following figure visualizes the described approach.
General Provisions
The general provisions describe the recommendations and / or requirements that should be followed when applying this solution.
Event Producer
- Event Producer is to be located in a FOLIO module acting as a Single Source of Truth
- Event Producer is to be located as close to Domain Data storage as possible
- If an application follows the pattern of splitting into 2 modules (business-logic & data-access) than Event Producer should be located in mod-*-storage
- Purpose is to reduce gap between a change in domain data storage and event publishing
- Transactional outbox pattern MUST be implemented in Event Producer to reliably update the Domain Data storage and publish events
- This is a trade off between consistency and performance since outbox introduces additional delay (maximum per polling interval)
Notification Channel (Kafka)
- Since Kafka is the main transport mechanism in this solution, the recommendations listed on the Apache Kafka Messaging System page should be taken into account
Event Consumer
- Processing a domain event on the side of the Event Consumer may include certain business logic (for example, checks, verifications, request for additional information, etc.) and work with the data storage. Worth noting that if the business logic and the data storage layer are located in the same module, this is an easier task than the case when the approach is used to divide them into two modules. In this case, the business logic and the data storage layer are separated by API calls, and the BL module itself does not have its own storage for implementing the Transactional Inbox approach. It seems that the choice of the location of the Event Consuming logic should be performed in each specific case based on the results of the requirements analysis - functional flow, performance expectations, etc.
- Commit of read messages to Kafka (so called acknowledgement) is to be performed after full processing only; auto-commit is not allowed
- The solution is to support at-least-one delivery, consequently Event Consumer MUST be idempotent and be able to process repeated event
Sequence diagramming
Below are two sequence diagrams that show the processes in more detail using the example of transferring a domain event from mod-inventory to mod-orders.
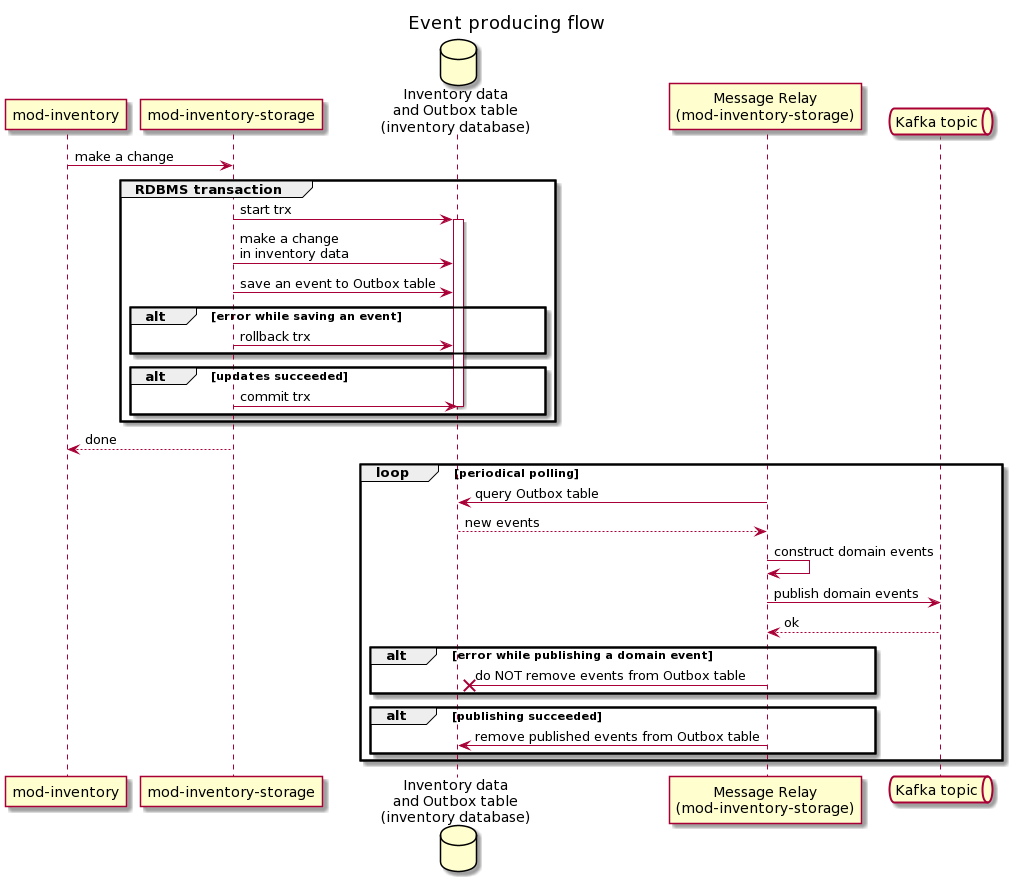
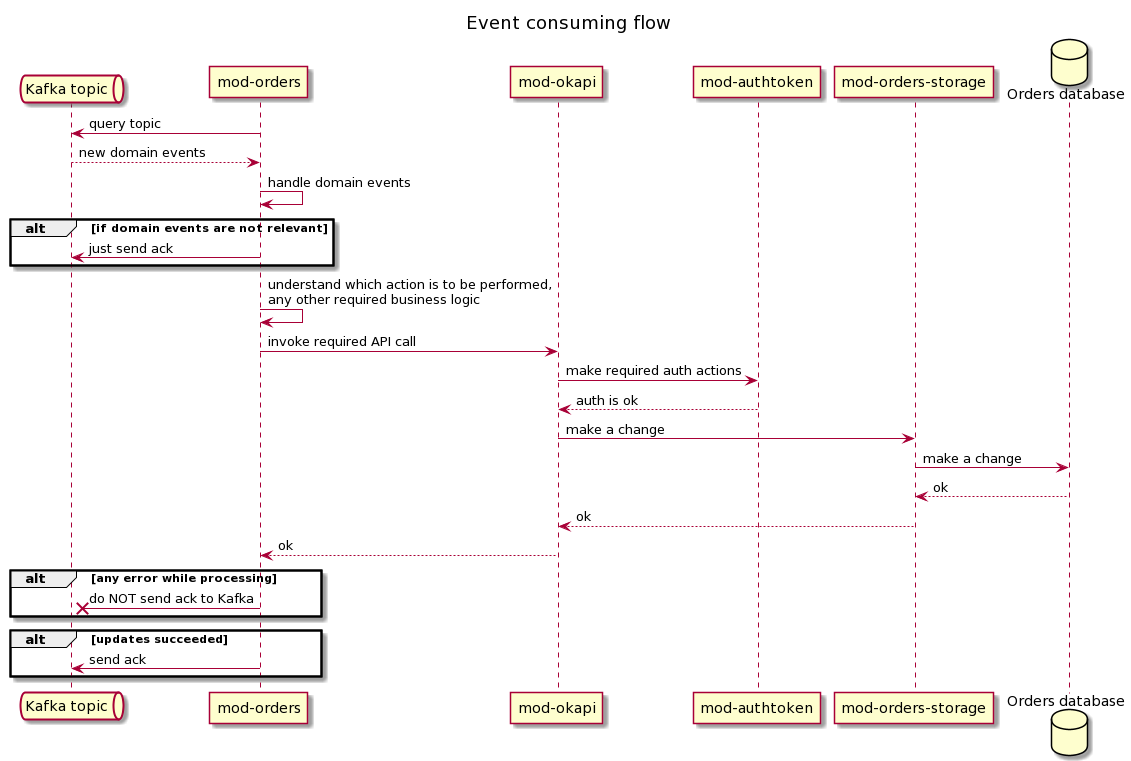
Development documentation
The proposed approach has already been actually implemented and is being used on FOLIO:
- mod-inventory-storage generates and publishes creation, modification, and deletion events for items, holdings, and instances. The independent consumers are mod-search, mod-search and mod-inn-reach,
- mod-inn-reach is also using mod-inventory-storage events and the developers there also implemented events for some circulation-storage models, as well (loans, requests, and check-ins),
- The infrastructure necessary to support the approach is already in-use (Kafka as the message broker).
Development documentation is available by the following links:
- https://folio-org.atlassian.net/wiki/display/FOLIJET/SPIKE%3A+%5BMODINREACH-78%5D+Record+Contribution%3A+Analyze+domain+event+pattern+implementation+in+mod-inventory-storage+and+mod-search
- https://folio-org.atlassian.net/wiki/display/FOLIJET/SPIKE%3A+%5BMODINREACH-80%5D+Record+Contribution%3A+Analyze+Re-Index+job+implementation+usage+in+mod-inventory-storage
Assumptions, Limitations, Challenges
- This proposal addresses use cases in categories a. Copies of data to be updated, c. Notify on deletion and e. Notify on data update; it does not address use cases in categories b. Notify use of data in other apps and d. Block on deletion
- It is possible to identify an application owning domain object/data in a particular use case
- Retention policy will always be long enough (at least 24 hours worth of record changes) for messages to be consumed by a receiving module
- The challenge of downstream OKAPI calls from the Event Consumer. It is very likely that when processing a domain event on the side of the Event Consumer, calling other FOLIO modules through OkAPI is required (for example, a business logic module interacts with a data store module, or another module needs to be called to obtain additional information). In accordance with the current permissions model used on FOLIO, to make such calls, one needs an OkAPI URL and a token. When transmitting messages through OkAPI, all modules follow this model and have all the necessary information to make calls. However, when sending messages through Kafka, the Event Consumer does not have such information, so 2 problems arise:
- Discovery problem - how to find out OKAPI URL for sending requests? Can be solved by passing an OKAPI URL from the Event Producer in the Kafka header of the message.
- Permission problem - how to grant permission to send requests to a specific module for a specific endpoint? Can be solved by adding and configuring System users.
- Discovery problem - how to find out OKAPI URL for sending requests? Can be solved by passing an OKAPI URL from the Event Producer in the Kafka header of the message.
- The challenge of consuming data in the appropriate order. It is fair to assume that a situation is likely when on the Event Producer side for the same domain object, several domain events can be generated, while it is important to keep the same order of transmission and processing of these events on the side of the Event Consumer. All components of this solution take part in addressing this challenge. The Event Producer is responsible for publishing events in the appropriate order. Kafka topics must be configured with the correct partition key, which will allow placing events related to the same domain object in one partition. Probably the most difficult task falls on the Event Consumer, who needs to be able to handle the events it receives sequentially.
- The challenge with having all relevant IDs on the Event Consumer side. During the discussion, the working group identified problems specifically with Inventory, where there is an hierarchical data model (Instance -> Holdings -> Items), and currently other applications do not necessarily store IDs for all aspects of this hierarchy. The assumption made is that applications will need to store all relevant IDs.
- Approach for initial data synchronization - this proposal is based on the assumption that the initial data synchronization, for example, when a new feature is released that requires data synchronization between different modules and / or applications, is performed during the data migration as a part of the feature release.
- Kafka as a transport mechanism takes a significant place in this proposal. This document does not cover the details of using Kafka and assumes that best practices for using Kafka have already been established.
- A case of a complete Kafka crash with the loss of all data is not addressed in this proposal.
Analysis and approaching Transactional outbox pattern
Transactional outbox pattern is required in Event Producer to reliably update the Domain Data storage and publish events. At the same time, keeping in mind scalability of FOLIO modules, another challenge should be approached - How are we intending to support multiple instances of modules? Will all instances process messages from the outbox or only one?
This part of the document contains an analysis of possible solutions to this issue.
In general, 2 main options can be considered
- processing by one single thread regardless of the number of module instances, and
- processing by 2+ competing threads (it does not matter where these threads work - within the same instance or across multiple instances)
(note: a thread in this context is a thread of execution in a program).
Option #1 with a single thread
More details on option #1. Need to have a service table, say, outbox_table_threads. It has the following fields - thread_id, onerow_uni, datetime (note, that onerow_uni should have a unique constraint specified).
Any starting thread generates its own random thread_id, remembers it in its memory, then tries to insert into outbox_table_threads values thread_id, true, current_datetime.
Note that with the Unique constraint, only 0 or 1 row is guaranteed to exist in the table.
Then the thread reads the same table. If thread_id from table == thread_id from memory, then the thread understands it won the election and can safely continue to work. This thread selects the top X events by insertion time, generates and pushes messages to the Kafka topic, and removes these top X from the database; and it's all in a cycle. There is no misordering, because the selection is sorted by insertion time, and only 1 thread is running.
If thread_id from table != thread_id from memory, it means that the thread is not allowed to perform any actions with outbox_table.
The elected thread runs as long as it can. At shutdown it would be necessary to stop it and clear the row of the table. But a) I'm not sure that it is possible on FOLIO to make some kind of callback when a module/thread stops, and b) the thread can still fall unexpectedly, so what to do?
To manage this situation, the elected thread periodically (period can be configurable) updates the datetime in outbox_table_threads (for example, every 60 s) as a marker that the thread is still alive and active.
All other available threads from other instances also periodically (well, the same 60 s) do repetitions. After an unsuccessful insertion attempt, a delete where datetime < 60 s * 2 operation is performed to remove info about the frozen elected thread, thereby allowing other threads to take part in the elections again.
Option #2 with concurrent threads
Option 2 is about multithreading. 2+ threads work with one outbox_table. As a rule, multithreading can be more performant though there are 2 main challenges - A with thread synchronization and B with misordering.
A - every thread should be able to lock a set of events in the table for processing. This can be achieved by select for update skip locked SQL statement https://postgrespro.ru/docs/postgresql/9.5/sql-select. Just a note here that I've previously met an issue with unlocking if the thread that created the lock could not explicitly release this lock for any reason (network problems, sudden stop of the thread, etc.), so the behavior in such conditions must be explicitly checked for Postgres / AWS Aurora. Another note is that the expected behavior can be also implemented on SQL without select for update.
B - potential misordering can happen when the first domain event was picked up by one thread, the second one was picked up by another thread, but the second thread processed its portion of data faster, so that the second domain event hits the Kafka topic before the first event. To address this, in fact, when selecting, it is necessary to skip those messages in which the entity ID has already been used in those messages that were selected earlier. It's something like marking somehow all selected events, and selecting new events counting those marked.
Conclusion
Both options (with one thread and with multiple parallel threads) are realizable. At the same time, option #1 is expected to be less productive (important - no measurements were taken, this is a general feeling and an assumption based on the fact that the data is processed in one thread), but at the same time more simple and understandable, and also easier to eliminate event disorder problems. Therefore, if option #1 allows you to meet a non-functional performance requirement, I would recommend using it.
Names of service tables and fields, work with them, flow logic - everything can be taken to a separate reusable library to improve overall approach usability and reduce required development effort.
List of open questions
- Outbox pattern in RMB
- The issue is with transactional work with DB
- https://debezium.io/ as an alternative to Outbox pattern
- Rollback as a compensation operation
- Re-writing DS module with Spring
- Inbox pattern in case of BL and DS separation
- Kafka exactly-once (check with Kafka documentation v. 2.4+)
- PII / sensitive data protection
- Filtering out of PII / sensitive data (similar to filtering while logging)
- Can be covered with Kafka authentication & authorization via certificates
- Resource consumption with full body
- Full body - minimum of OkAPI
- Only dif for updates? Binary format for Kafka messages
- Message priority
- Priority topics
- https://stackoverflow-com.translate.goog/questions/30655361/does-kafka-support-priority-for-topic-or-message?_x_tr_sl=en&_x_tr_tl=ru&_x_tr_hl=ru&_x_tr_pto=sc ??
- Retention period
- Should be long enough
- Initial sync
- Initial migration
- Complete loss of events
- Kafka backups on level of hard disk
- Version compatibilities
- What to do if Event Consumer receives an event of a newer version?