Folio logging solution
- Mikhail Fokanov
- Taras Spashchenko
- Craig McNally
Problem statement
There should be platform wide solution for logging aggregation in order to quickly identify and find the root causes of issues
Log entries for the same business transaction in different microservices should have request id in order to find all log entries for the same business transaction
There should be configurable alerting in order to get information about new the issues as soon as possible (is supposed to be handled by hosting provider)
Current state
Okapi aggregates logs from all applications into single file.
Logging Solution
Java logging library
Logging java library Log4j2 was initially used for implementation of core modules. All other java modules should use Log4j2 for logging to provide seamless integration of common logging approach.
Logging facilities provided by RMB
In order to include request information RMB based modules will be able to leverage FolioLoggingContext after implementation of RMB-709 - Getting issue details... STATUS (which is blocked by Vert.x 4 release and migration). For now this is implemented only in OKAPI.
In case of non-RMB java modules the Mapped Diagnostic Context (MDC) can be leveraged in cases when it is possible. There should be implementation of mechanism in order to supply request headers to MDC. (e.g. MDC.put("requestId", "some-id");)
When user request routed to multiple, different microservices and something goes wrong and a request fails, this request-id that will be included with every log message and allow request tracking.
Usage of Log4j 2 Layouts
An Appender in Log4j 2 uses a Layout to format a LogEvent into a form that meets the needs of whatever will be consuming the log event. The library provides a complete set of possible Layout implementations. It is recommended to use either Pattern or JSON layouts in FOLIO backend modules. By default, the Pattern layout should be used for development, testing, and production environments. In the cases when log aggregators are used in particular environments, the usage of JSON layout should be enabled explicitly for all backend modules by the support/deployment teams.
All FOLIO backend modules must provide configuration property files for both layouts (Pattern and JSON). In addition, recommended default logging configurations are provided by the respective libraries (folio-spring-base, RMB).
Default configuration for JSON Layout
For any logging aggregation solution json format of logs is preferable over plain text in terms of performance and simplicity of parsing. All Folio modules should have the same json format for logs, e.g. the following:
For Spring Way modules https://github.com/folio-org/folio-spring-base/blob/master/src/main/resources/log4j2-json.properties
For RMB modules https://github.com/folio-org/raml-module-builder/blob/master/domain-models-runtime/src/main/resources/log4j2-json.properties
Default configuration for Pattern Layout
For Spring Way modules https://github.com/folio-org/folio-spring-base/blob/master/src/main/resources/log4j2.properties
For RMB modules https://github.com/folio-org/raml-module-builder/blob/master/domain-models-runtime/src/main/resources/log4j2.properties
Logging aggregation stack
The deployment and configuration of logging aggregation stack is responsibility of hosting provider. See below the example of configuration for logging stack using EFK:
EFK
The goal of centralized logging stack is quickly sort through and analyze the heavy volume of logs. On of the most popular centralized logging solution is the Elasticsearch, Fluentd, and Kibana (EFK) stack.
Pros:
- There could be Elastic deployed within platform for full-text search, so it wouldn't be additional technology in the stack
- Fluentd is used instead of Logstash, because the latter has certain performance problems and not so simple in terms of configuration
Cons:
- There tools with richer functionality (e.g. datadog)
Elasticsearch is a real-time, distributed, and scalable search engine which allows for full-text and structured search, as well as analytics. It is commonly used to index and search through large volumes of log data, but can also be used to search many different kinds of documents.
Elasticsearch is commonly deployed alongside Kibana, a powerful data visualization frontend and dashboard for Elasticsearch. Kibana allows you to explore your Elasticsearch log data through a web interface, and build dashboards and queries to quickly answer questions.
Fluentd will be used to collect, transform, and ship log data to the Elasticsearch backend. Fluentd is a popular open-source data collector that we’ll set up on our Kubernetes nodes to tail container system out (or log files), filter and transform the log data, and deliver it to the Elasticsearch cluster, where it will be indexed and stored.
Alerting
There are many plugins available for watching and alerting on Elasticsearch index in Kibana e.g. X-Pack, SentiNL, ElastAlert. Alerting can be easily implemented in Kibana (see: https://www.elastic.co/blog/creating-a-threshold-alert-in-elasticsearch-is-simpler-than-ever)
Elastalert is open source simple and popular open source tool for alerting on anomalies, spikes, or other patterns of interest found in data stored in Elasticsearch. Elastalert works with all versions of Elasticsearch.
Deployment options
K8s deployment
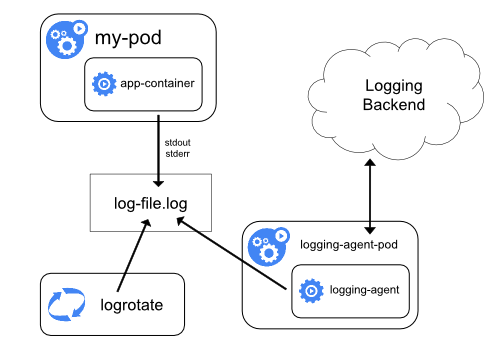
Separate kube-logging namespace should be created into which EFK stack components should be installed. This Namespace will also allow one to quickly clean up and remove the logging stack without any loss of function to the Kubernetes cluster. For cluster high-availability 3 Elasticsearch
Pods should be deployed to avoid the “split-brain” issue (see A new era for cluster coordination in Elasticsearch and Voting configurations).
K8s deployment: Kibana
To launch Kibana on Kubernetes Service called kibana should be created in the kube-logging namespace. Deployment consists of one Pod replica. Latest kibana docker image located at: docker.elastic.co/kibana/. Range of 0.1 vCPU - 1 vCPU should be guaranteed to the Pod.
K8s deployment: Fluentd
Fluentd should be deployed as a DaemonSet, which is a Kubernetes workload type that runs a copy of a given Pod on each node in the Kubernetes cluster (see: https://kubernetes.io/docs/concepts/cluster-administration/logging/#using-a-node-logging-agent).
Folio modules should use single common slf4j configuration, for writing JSON logs on the nodes. The Fluentd Pod will tail these logs, filter log events, transform the log data, and ship it off to the Elasticsearch. Fluentd DaemonSet spec provided by the Fluentd maintainers should be used along with docs provided by the Fluentd maintainers: Kuberentes Fluentd.
Service Account called fluentd that the Fluentd pods will use to access the Kubernetes API should be created in the kube-logging namespace with label app: fluentd (see: Configure Service Accounts for Pods in the official Kubernetes docs). ClusterRole with get, list, and watch permissions on the pods and namespaces objects should be created.
NoSchedule toleration should be defined to match the equivalent taint on Kubernetes master nodes. This will ensure that the DaemonSet also gets rolled out to the Kubernetes masters (see: https://kubernetes.io/docs/concepts/configuration/taint-and-toleration/).
https://hub.docker.com/r/fluent/fluentd-kubernetes-daemonset/ provided by the Fluentd maintainers should be used. This Dockerfile and contents of this image are available in Fluentd’s fluentd-kubernetes-daemonset Github repo.
The following environment variables should be configured for Fluentd:
FLUENT_ELASTICSEARCH_HOST: Elasticsearch headless Service address defined earlier:elasticsearch.kube-logging.svc.cluster.local. This will resolve to a list of IP addresses for the 3 Elasticsearch Pods. The actual Elasticsearch host will most likely be the first IP address returned in this list. To distribute logs across the cluster, you will need to modify the configuration for Fluentd’s Elasticsearch Output plugin (see: Elasticsearch Output Plugin).FLUENT_ELASTICSEARCH_PORT:9200.FLUENT_ELASTICSEARCH_SCHEME:http.FLUENTD_SYSTEMD_CONF:disable.