| Slide 17: - Provide a more transparent way of understanding what FOLIO did when batch processing
- Better understanding of what a failure means -- did it revert the record, delete the record, invalidate the record?
- Itemize failures so it’s easy to identify affected records, e.g. “record #XXXXXX failed,” not “7 of 10,000 changed failed”
- Pay particular attention to global failure where feedback is especially spare
- Give some indication, if possible, of how failure can be avoided
- Provide some indication on how to re-try or follow-up from a failure
Slide 19 - Optimize .csv files for understandability
- Make it very clear which fields can or should be edited and which should be avoided (in app or local edits?)
- Provide some degree of instruction on how to make changes to commonly edited fields like status and location (in app?)
- Give users the power to rollback changes upon upload if files are corrupted or mistakes were made (pre-update records stored in S3)
- Anticipate potentials error and provide warnings, e.g. “Is this correct?,” “Are you sure?”
Mockup- file upload | Mockup - are you sure | Mockup - delete modal | Mockup - delete errors | Mockup 5 - file upload .png?version=1&modificationDate=1639859876000&cacheVersion=1&api=v2&width=640&height=400)
- Magda: The user has uploaded the file with the IDs but there were errors while the reports were being matched.
- Magda: You submitted 302 records. You get only 300 because we did not find a match for one. And the other one was was duplicate.
- Magda: No changes have actually happened yet. This is a preview of the records.
- Erin: Is the preview of the records showing me what is in the file or in the system or both?
- Magda: Your file contains only the list of your UUIDs, nothing else. This data comes from the user table.
- Magda: The preview pulls from the top of the list. It will list the top 10 records in the implementation.
- Magda: This is showing the user why only 300, not 302 were matched and reason.
Mockup 6 - actions dropdown 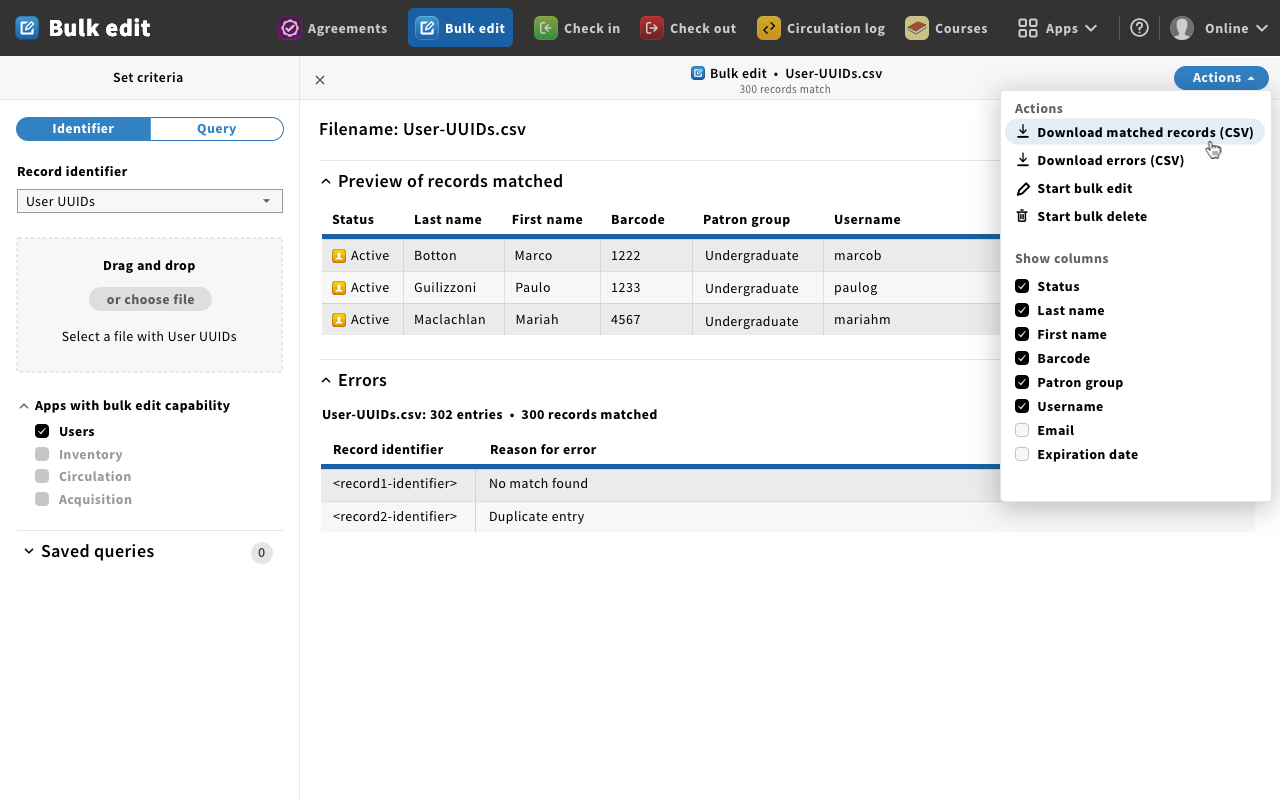
- Bob: Can you export those?
- Magda: You can download the matched records and download the errors from here in CSV format.
Mockup 7 - download matched records 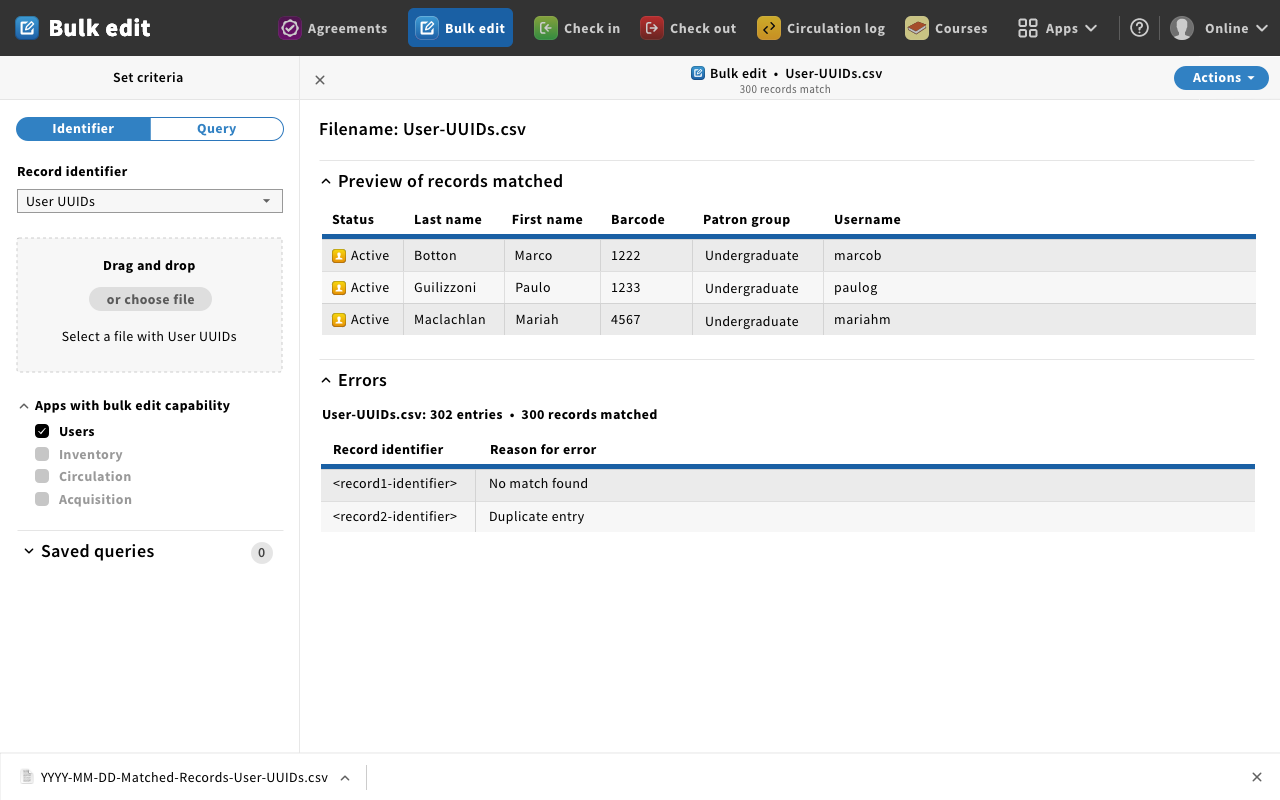
- Magda: This is the example of saving the file with the records that we marched with the standard naming convention displayed at the bottom.
Mockup 8 - actions dropdown start bulk edit 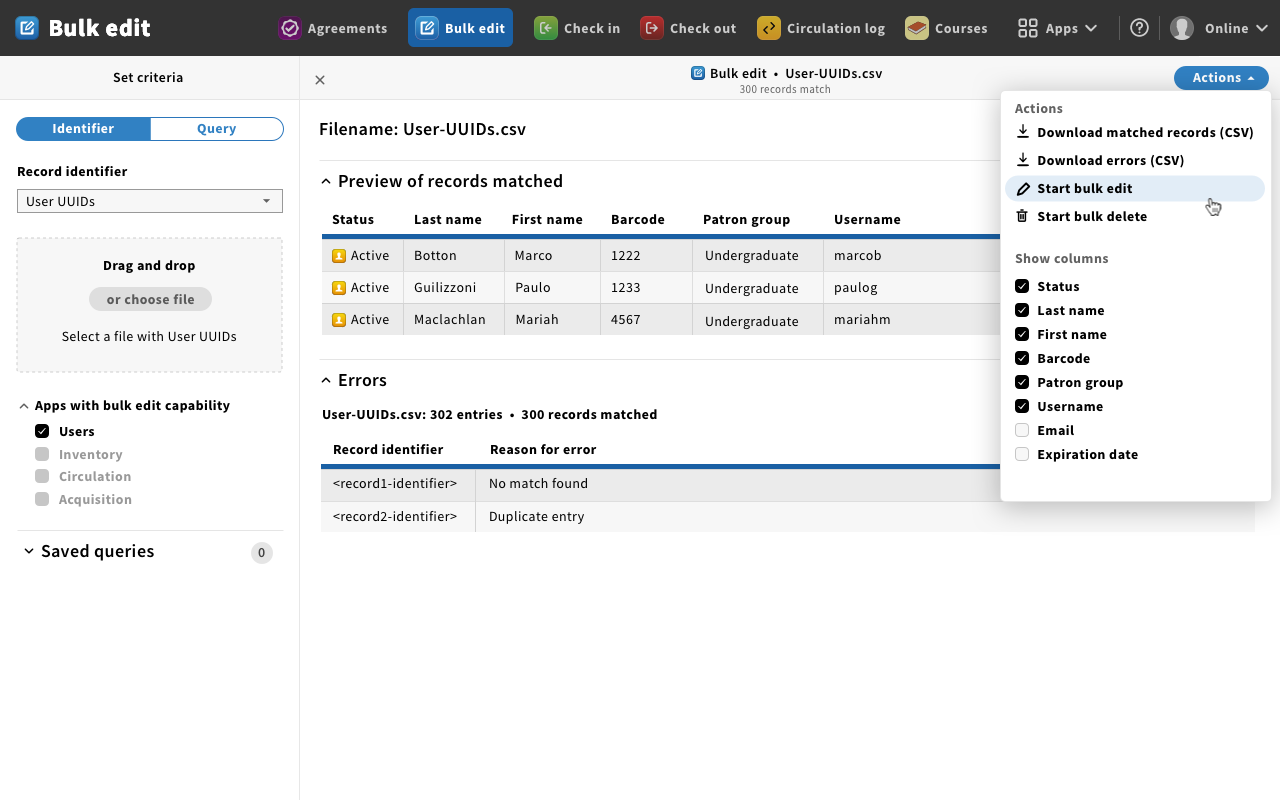
- Magda: This is an example of starting the bulk edit process.
Mockup 9 - bulk edit modal 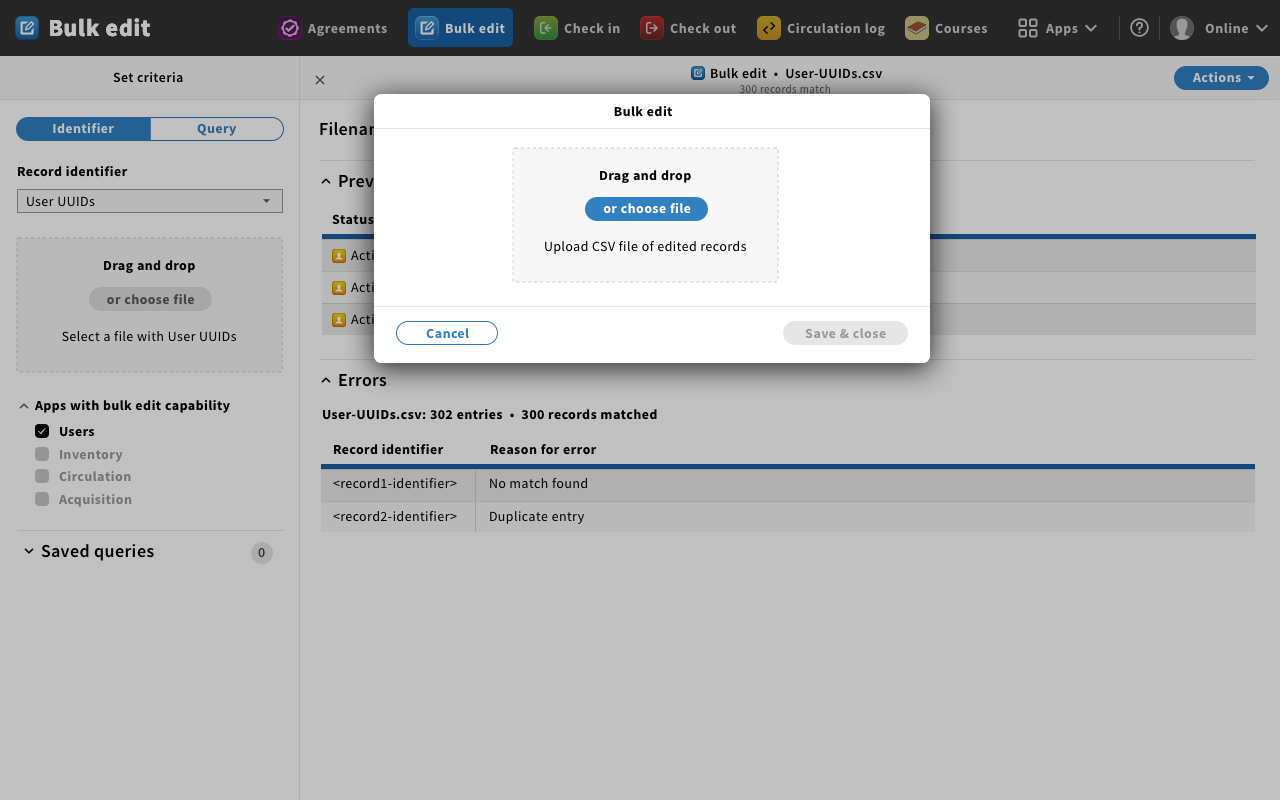
- Magda: Example of uploading the file from your local machine with changes you made locally.
Mockup 10 - drag and drop
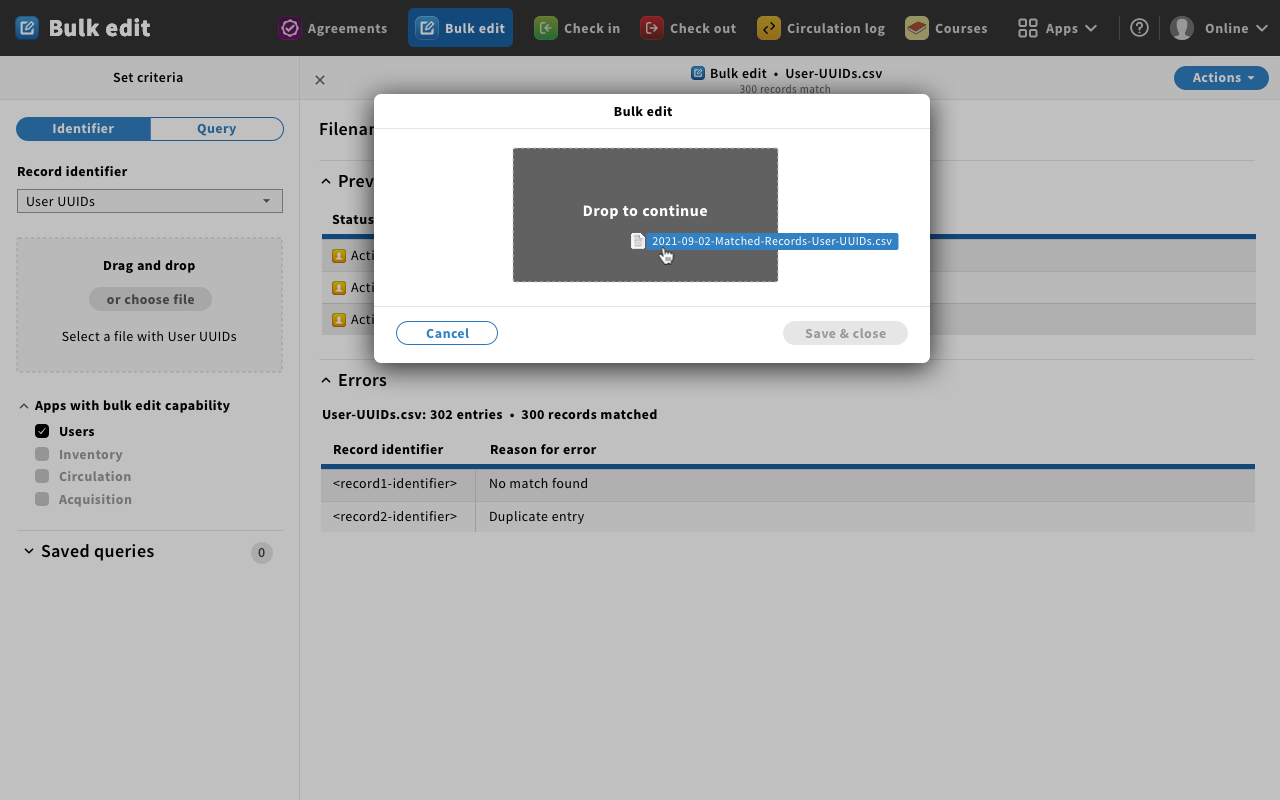
- Magda: This shows the process of dragging and dropping the file to upload. You can also browse to the file via your local computer's file system.
Mockup 11 - bulk edit confirm
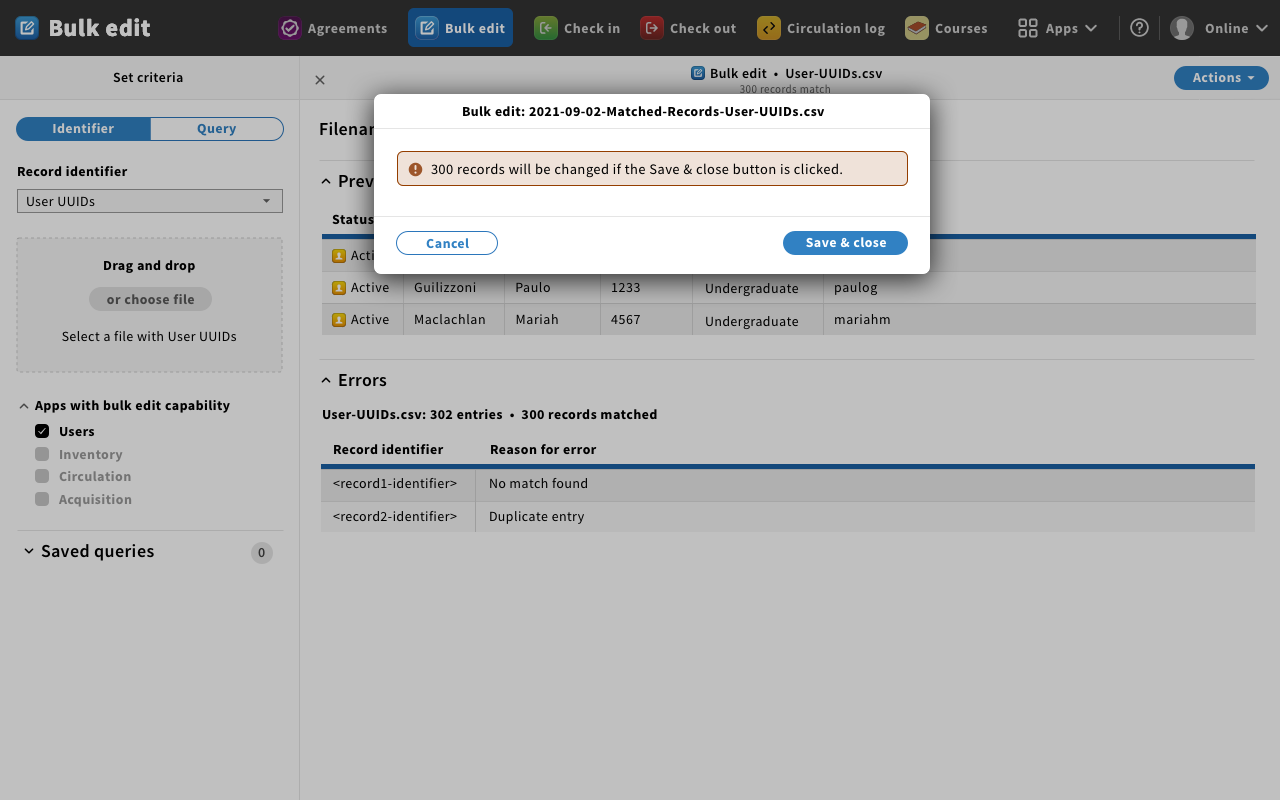
- Magda: You uploaded the file with your changes. This message is letting the user know that once you click save & close, 300 records will be changed.
- Don: Are the records you are working on locally locked in the system while you are doing this?
- Magda: No (I did not hear any elaboration on this point that Dan brought up)
Mockup 12 - progress bar
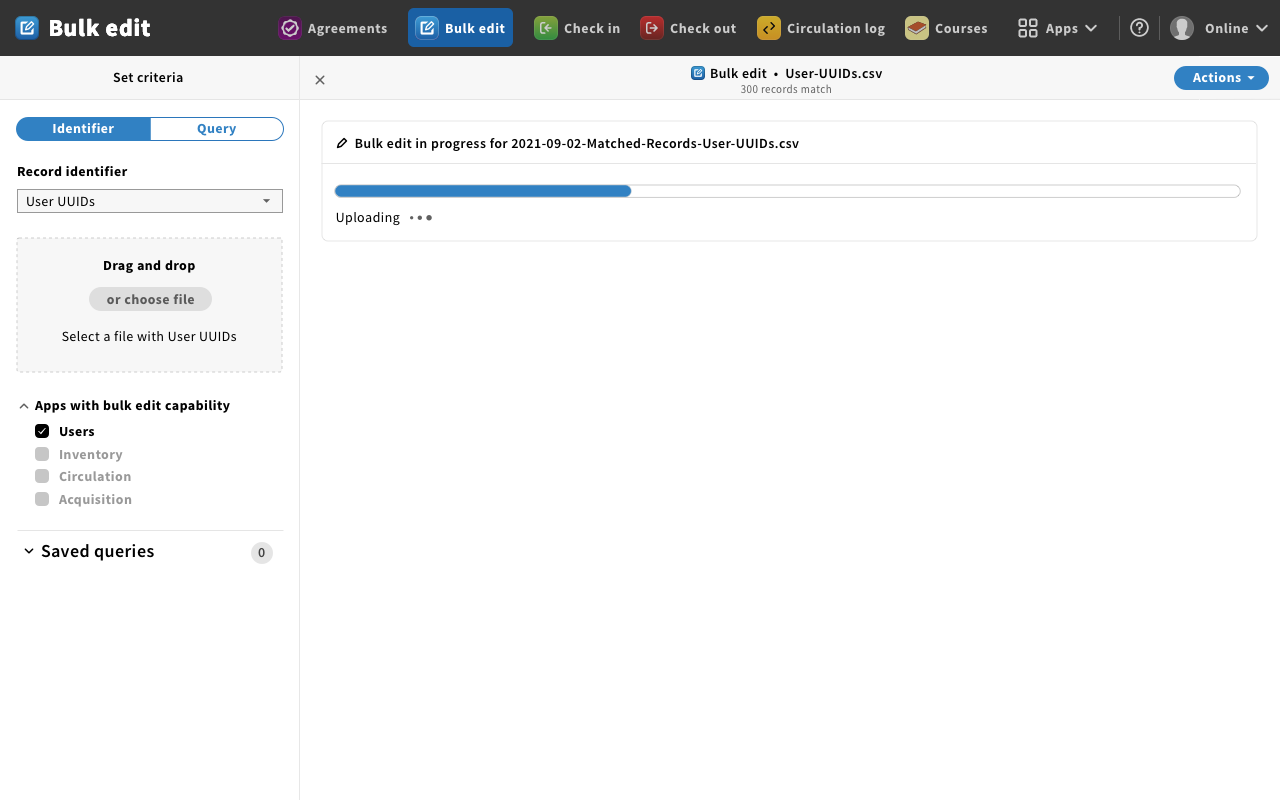
- Magda: The uploaded file is being processed on the backend.
- Magda: The progress bar is provided to monitor the progress.
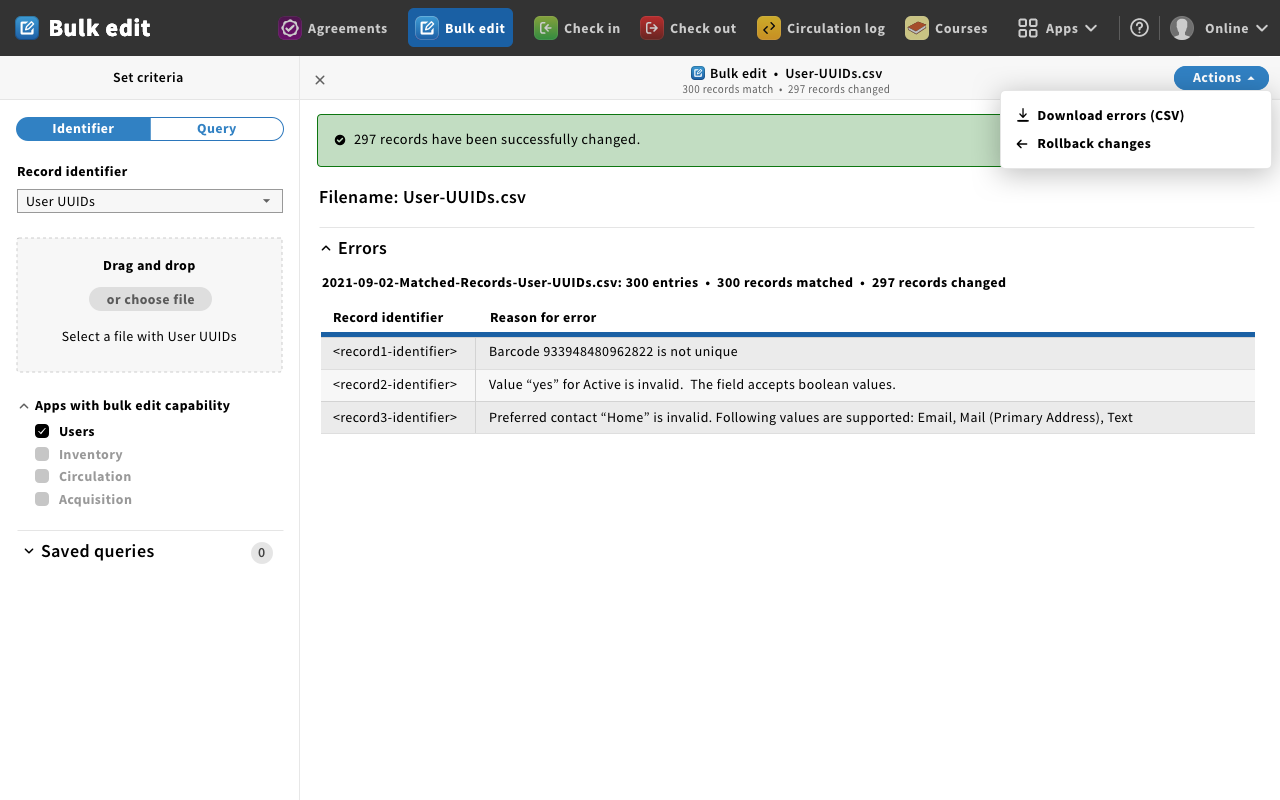
Mockup 13 - success 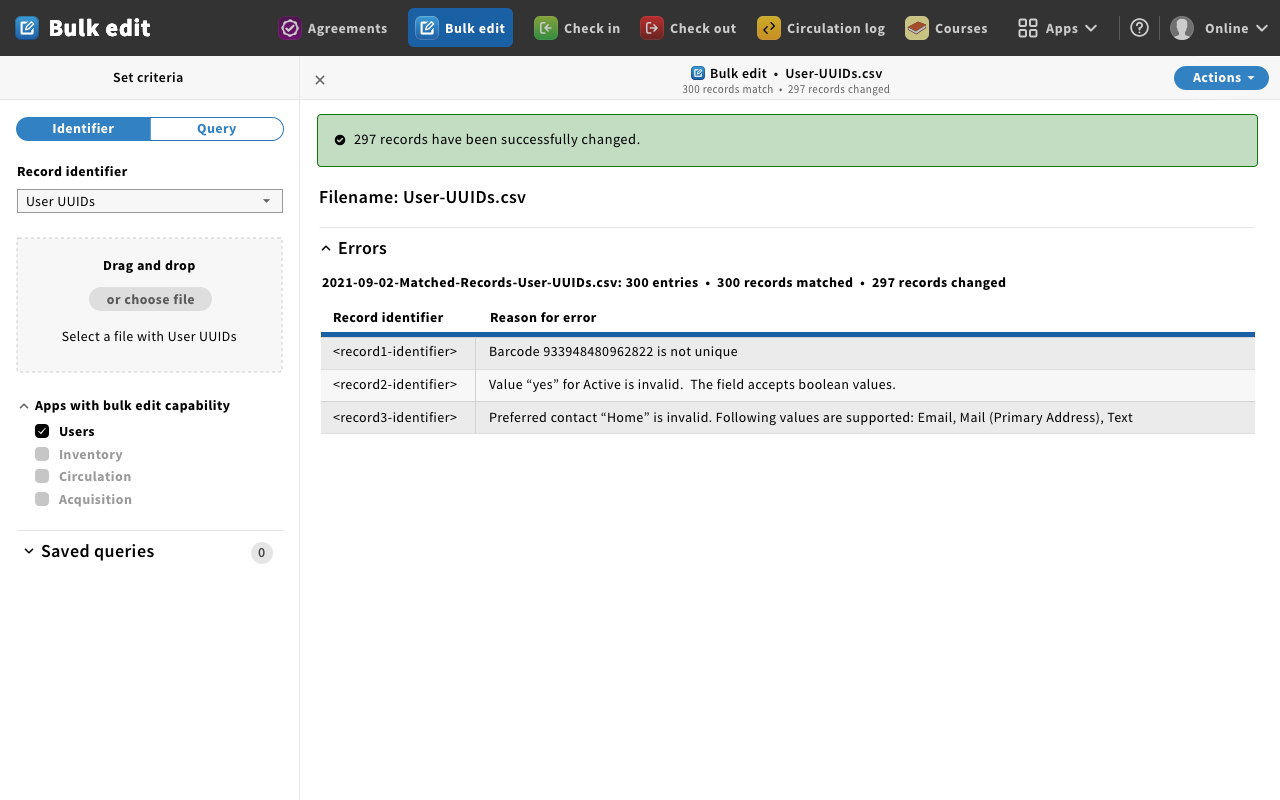
- Magda: Process completes with a message to the user that 297 records were changed the way you specified.
Magda: However, there were some errors. One of the barcodes that you provided was not unique. So the record was not processed, and the record in the FOLIO was unchanged from what it was before you began the process. You provided invalid data. You wanted to change some of the users to be active, but you provided populated it with the word "Yes" when the value should be true or false. - Preferred contact data was also invalid. You provided the word "Home" when valid values can only be "email" "mail" or "text."
- Thomas: With the data upload, do you have to return the full CSV file, or can you just return the fields you want to be updated? By only sending the data you want to be updated lowers the chance that you would change another field that may have been changed in the system by another user in the interim when you were working on the file locally.
- Magda: This is a very good point and I will bring it up with the developers.
- Erin: If you are not sending back all the fields you have to be very careful that your mappings are absolutely correct. Example: sending 500 email addresses mapped to the first name field.
- Christie (Comment via chat): There's also the chance of data corruption introduced by the tool that you are editing the data with outside of FOLIO. So I think the safest option is to send just the data that has changed.
- Bob: One system that I use has a mapping confirmation process built into the interface. You can see it here: https://help.memberclicks.com/hc/en-us/articles/230535007-Profile-Import.
- Sara: It's not even that we have to introduce corruption. It can also be even within a very short amount of time, not days of having the file out and then putting it back. Somebody finds a typo in a person's name and fixes it. And then if I overlay the record completely, then I just put the error back. I think that's also something we have to keep in mind that going forward is that we can have the option to either put or patch and we should be able to distinguish between the two. Sometimes you want to totally overlay a record. Then also very often you just want to correct a very specific part. And I think we do need to have that capability of being able to do that safely. To add a line without saying that we're going to overlay it all again. I can do that with my current system.
- Magda: When you say add a line do you mean to add a new record?
- Sara: No I mean adding for example emails to records where that data element is missing in some of the records.
- Magda: So when you get the file from the system, you will have the email column. In your example, the email column will be empty. So then you would populate that.
- Sara: Are you were saying that all columns are always present, whether they have value, values associated with them?
- Magda: Yes.
- Magda: I would like to make a comment about the patch and put in post methods. To be honest, I'm not sure in FOLIO if we support patch. Maybe we do, but I know most APIs that I worked with support the post method the new records and put for modifications.
Magda: I see the problem with what Sarah mentioned, someone changed or corrected the name of the user. And we are overwriting the data. And to be honest, at this point, I don't have a quick and easy solution for that. This may happen. Definitely. - Don/Mark?: You can use get then put to achieve essentially the same things as a patch.
- Magda: Also something to consider. I will discuss this with the developers.
- Christie: I do think that if you're just changing one property like location, the easiest thing to do is to just replace that JSON object in the record, and that's the safest thing to do. I'm just wondering whether or not this model supports the ability to null things. And I think that you would have to do a replacement of the whole record if you wanted to remove a value because of how nulls are represented in JSON.
- Christie: I wanted to point out that we have this issue in data import, and I don't know what the commands are for working with the data via the API, but there's a difference between an overlay and a merge, right? You want to replace the whole record, or you just want to add a new property to the record, or a new value for that property, or you want to replace a previous property with a new property, or you want to remove a value. And being able to just impact that one file is really powerful, especially because of the business logic that is sometimes triggered by these operations.
You could be having an impact on the data that is not explicitly changing a value. So I do think that there is a need to be able to do that. Again, I'm using the terms from data import that we have settled on, overlay, which has replaced the entire record, and merge, which is just replacing or somehow otherwise modifying some of the data that is targeted.
- Magda: I understand your point, Christie. I think what we do, and I think this comes from the software development approach, is editing. Editing the record includes removing the data, adding the data, or updating, changing the value of the data, but this is happening on the record level and the properties. So you can populate a property that did not exist, remove the value of the property that was populated, or change the value. And you said a couple of things that are very important. One of them it's merging the records. And from what you're describing, you understand the merging as the changing one property of the record, right?
And then let's say the last name has changed for the user and everything else stays as it is. So you would call this merging of the record, right? You are updating only one property of the record. I understand that as an update, you are updating one field. If you get the copy of the record on Monday, and on Tuesday someone realized that there is a typo in the first name, and then you are uploading the file again on Wednesday. And your file has a first name and last name. The first name is not changed. And their last name was modified to the new value you wanted to change. And you send the request to the user API. What will happen? You will overwrite the Tuesday changes to the first name, and you will add the last name update the way you want it. Does it make sense? - Christie: It does make sense. I just think that we would want to be very careful. I realized that we're talking specifically about users here, but I'm extrapolating it to the type of data that I work with, which is pretty much everything but users. So, maybe I'm thinking more of the UIs we use. I think that this model isn't traditionally how we have thought about editing records in batch. So, I think it's going to be very important to have a lot of documentation about what you are doing because you every system that I've worked with if I need to change the location, all I have to do is submit the record ID and the location. And I can see somebody accidentally wiping out everything but the location and their holdings records.
- Magda: Christie, this is an additional argument for having an in-app bulk edit that would allow you to change just one field. You probably, in the long run, will not use the CSV approach If you want to change one field. You will probably go with the in-app approach. And what you said about you working with other records types except for users, what we are trying to do in the bulk edit pilot project is set the expected behavior and then build on this for other record types. So definitely the feedback you are providing here is helpful.
- Jen: I just want to echo Christie in that I'm still not understanding why the CSV has to have all of the fields in it instead of only the ones you want to update. Having only the ones you want to update makes a lot more sense to me. But then the other thing I was going to say is we've introduced versioning. If we export the version to a column in the CSV, then that could be used to make sure the version didn't change since we export it to CSV.
- Magda: I don't think users supports optimistic locking.
- Jen: But bulk edit could. Because all it has to do is say this is version four, is the version I'm updating also version four, kind of doing it on its own. I guess I just agree that passing a bunch of data that you aren't actually trying to update seems like asking for trouble.
- Magda: I would like to use the last 15 minutes to show you a little bit more about what we put in place or what we are in the process of putting in place to avoid corrupting the data in case something goes wrong.
I think we discussed a lot of important issues and I'm sure we will come back to this. But I want to show you two things. One, when you are uploading your list of UUIDs or identifiers, we are storing the list in S3 or MinIO if you are not using Amazon web services. If you are downloading the file with the changes you want to make, we keep the list as well. So in case, you make changes that corrupt the system, we will be able to revert those changes.
- Mockup 13 - success2
So what will happen is we will get the file that we stored on the system and apply the file. You will get the system to the place where it was before you uploaded the changes. Assuming you had errors you can go back to the original file that you submitted, make the changes in the file, and then go back to start a bulk edit again and submit the file. We have 10 minutes left. I would like to finish the slides today so that next time we meet we can go over the survey results about the permissions and limits. We implemented permissions and I tried to use your feedback, but definitely, we will need to revisit that.
- Slide 17 from Ryan's Presentation
.png?version=1&modificationDate=1639952578000&cacheVersion=1&api=v2&width=650&height=365)
Slide 17: - Magda: Provide a more transparent way of understanding what FOLIO did when batch processing.
- Magda: Better understanding of what a failure means - did it revert the record, delete the record, invalidate the record?
- Magda: It means that the update did not occur.
- Magda: Itemize failures so it’s easy to identify affected records, e.g. “record #XXXXXX failed,” not “7 of 10,000 changed failed,”
- Magda: I think our logs address that.
- Magda: Pay particular attention to global failure where feedback is especially spare.
- Magda: Any comment on this?
- Magda: Give some indication, if possible, of how failure can be avoided.
- Magda: I believe in our logs we are trying to address those.
- Provide some indication on how to re-try or follow-up from a failure.
- I do believe that the screenshot of the mock-ups that I showed you addresses those issues.
- Thomas: I'm wondering with the itemized failures, instead of just giving the record number if you could also give a line number in the CSV file it might be helpful for the user?
- Erin: The record number would need to be easily identifiable.
- Magda: This may be an incorrect approach, but I thought if I give you the identifier of the record, it will be the best way to find it. Not even that the line may not be that applicable. I think providing the line may be a little bit more involved when it comes to the implementation. I'm not sure how accurate it could be, but I will put it on my list to double-check.
- Slide 19 from Ryan's Presentation
.png?version=1&modificationDate=1639954831000&cacheVersion=1&api=v2&width=650&height=365)
- Slide 19:
- Magda: What do you mean by optimize CSV files for understandability?
- I think the line about optimizing for understandability is sort of getting into the second part of that, which is avoiding Ebsco or vendor-centric jargon or codes. I don't think that's really an issue for users per se, but if you were doing something with agreement records or something else that was really vendor-specific, you would not want, to have default language that could only be understood if somebody was a Gobi user for example. I think that's more of what that means.
Magda: Okay. So, to be honest, I'm not sure what do you mean by EBSCO-centric jargon or code? If I use the Ebscp-centric jargon or code, you will need to bring it to my attention because I may not be aware of it.s Erin: I would say vendor-centric. Like using codes or language that is from a specific platform, trying to be as nonvendor specific as possible. Erin: I will ask all the groups to pay attention and bring it up to my attention and let me know if this is happening. Erin: I think that's a reasonable request. Magda: It's not only that I'm working with Ebsco for nine years now. I learned the language while working at Ebsco. So some terms I may think to have a general meaning and if they don't, then please let me know.
Magda: Make it very clear which field can or should be edited and which should be avoided. Magda: This line is definitely applicable for in-app edits where we control what can be edited or not. Magda: In the CSV we rely on the user to know what they are doing. And if the user doesn't know, we will catch the error while updating the record and ignore it. The record will not be updated.
Magda: Provide some degree of instruction on how to make changes to common fields like status and location. Magda: When you say provide some degree instruction do you mean this as documentation or when you try to do something in the UI and the UI should prevent you? This is again more applicable for in-app bulk edits. What do you mean by some degree of instructions? Erin: I think this is Ryan's language. I don't know if this is necessarily the language that the specific participants used, but I would interpret that as saying that there needs to be really good documentation on how to do the common or most expected processes within the app. Whether that is external to the app somehow but available to everyone, or whether that is inside the app, I think this is a question. But I would interpret that as saying documentation.
Amanda: You're getting at that a little bit in the examples of the error messages that you were showing with the CSV, like one of them says this value needs to be Boolean instead. So that would be helpful to know upfront, but also with the preview mode, you're getting feedback at least. Magda: Okay, I understand you would like to know before you submit the file. As I said, this would be probably more applicable for the in-app option where we would be able to control the vocabulary that is being entered.
Give users the power to roll back changes upon upload, if files are corrupted or mistakes were made. Magda: Anticipate potential error and provide warnings, e.g. “Is this correct?,” “Are you sure?” Magda: We have one "are you sure" message before you trigger the bulk edit. But once you start the process, you see the progress bar. Do you think you would like to see the errors displayed as they occur during the progress, or is it okay if we show them once the update is complete? Amanda: I think once the update is complete is fine.
Erin: Magda, It looks like we're at 11 o'clock. Magda: Yes. Thank you, Erin. Thank you all for the feedback. Our next meeting starts in the new year with the limits and permissions and some additional changes that will be more applicable for other areas, as we will need need to start planning for Morning Glory. Hopefully, by then, we will have the environment for you to start playing around and provide your feedback as well. If you have any questions, comments, please reach out to me on Slack anytime and happy holidays and happy new year
|