Error rendering macro 'jira' : Unable to locate Jira server for this macro. It may be due to Application Link configuration.
Overview
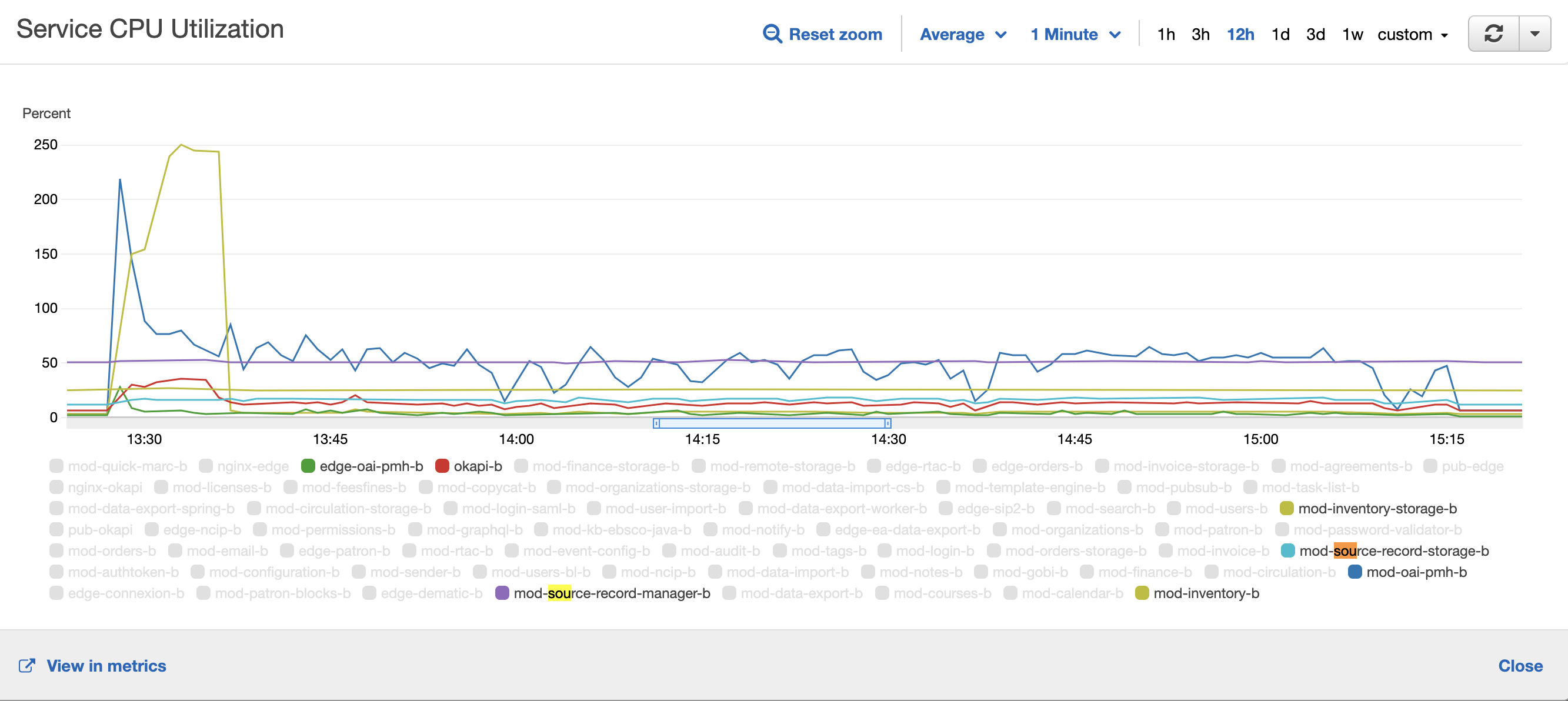
As was mentioned in Jira - there is huge performance degradation between releases iris - juniper. According to Jira - previously harvesting process of 350K records takes ±2 hour and now on Juniper release it takes 4 hours.
Test flow
Test consist of few calls:
Initial call:
- /oai/records?verb=ListRecords&metadataPrefix=marc21_withholdings&apikey=[APIKey] - performing only once
Harvesting call:
- /oai/records?verb=ListRecords&apikey=[APIKey]&resumptionToken=[resumptionToken] - performing repeatedly until there is no more data in [tenant]_mod_oai_pmh.instances table to harvest.
[resumptionToken] returning in initial call response and in each harvesting call until there is no more records to harvest. When all data has being harvested - resumptionToken will not return with hte response.
Environments to test on:
- ICP1 - Iris release;
- JCP1 - Juniper release;
- IMTC1 - Latest Juniper release (and more powerful environment).
Software versions
| IMTC1 (Juniper) | JCP1 (Juniper) | ICP1 (Iris) |
|---|---|---|
| mod-oai-pmh:3.5.0 | mod-oai-pmh:3.5.0 | mod-oai-pmh:3.4.2 |
| edge-oai-pmh:2.3.1 | edge-oai-pmh:2.3.1 | edge-oai-pmh:2.3.1 |
mod-source-record-storage:5.1.5 | mod-source-record-storage:5.1.6 | mod-source-record-storage:5.0.6 |
| mod-source-record-manager:3.1.3 | mod-source-record-manager:3.1.3 | mod-source-record-manager:3.0.9 |
| mod-inventory-storage:21.0.3 | mod-inventory-storage:21.0.3 | mod-inventory-storage:20.2.2 |
| okapi:4.8.2 | okapi:4.8.2 | okapi:4.7.3 |
Test results
Harvesting of 350K records.
| ICP1 (Iris) | IMTC1 (Juniper) | JCP1 (Juniper) |
|---|---|---|
| 1 hr 47 min | 1 hr 14 min | 45 min |
| 1 hr 26 min | 1 hr 10 min | 42 min |
| env | ICP1 (Iris) | IMTC1 (Juniper) | JCP1 (Juniper) |
|---|---|---|---|
| instances | 8,072,048 | 756,417 | 7,252,127 |
| SRS records | 1,186,613 | 597,223 | 710,371 |
Conclusions:
- As you can see from table above - we can say that Juniper release at least not slower than Iris release, or even faster.
- We can see slowness on IMTC1 env (it should be more powerful than others). However it's still better or the same as ICP1 (Iris).
- The only difference between IMTC1 and JCP1 is state of DB (different data set may affect the performance). Between IMTC1 and JCP1, the difference here is the proportion of SRS records relative to the instance records. IMTC1's harvesting time may be slower because there are more SRS records to process per instances than with JCP1 instances.
- We'll need additional tests on same data set but on different releases.
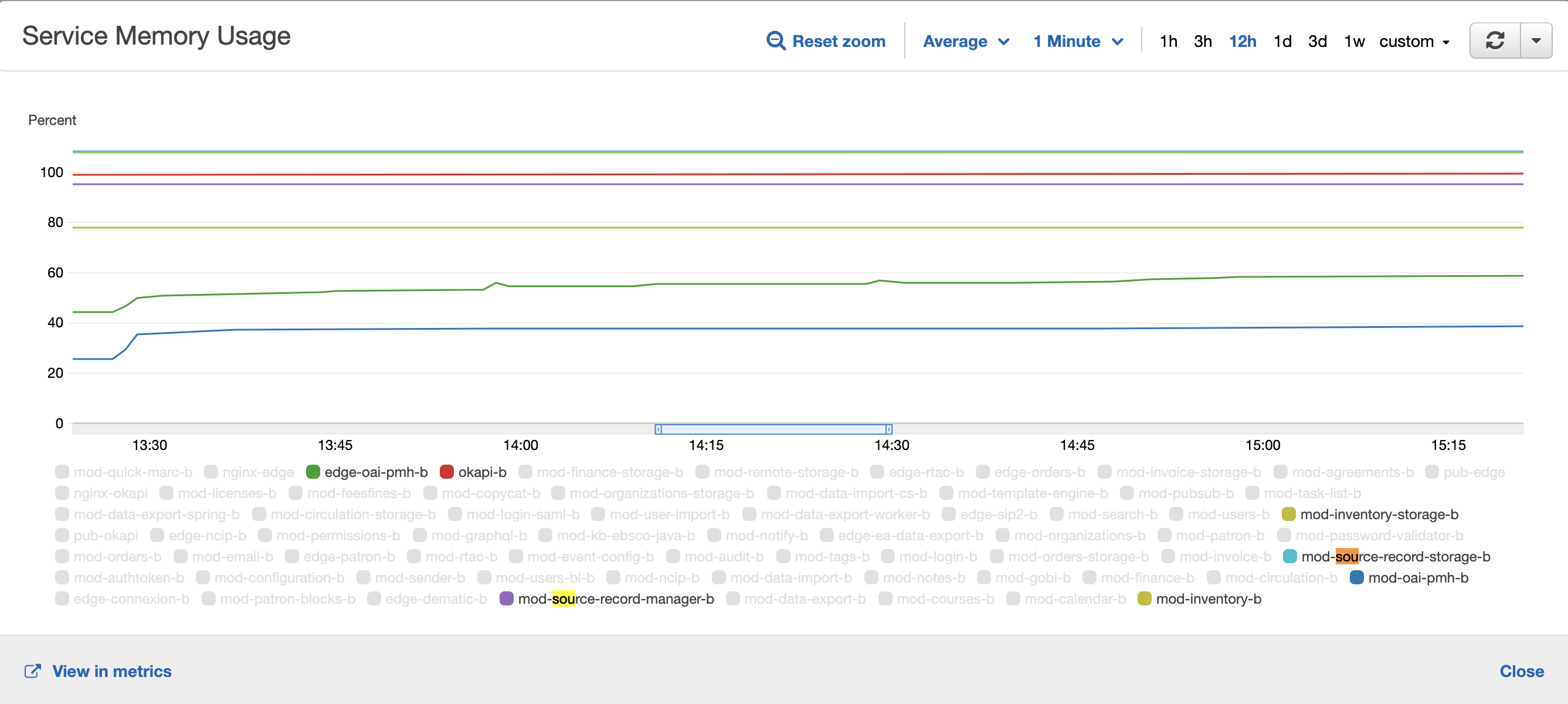
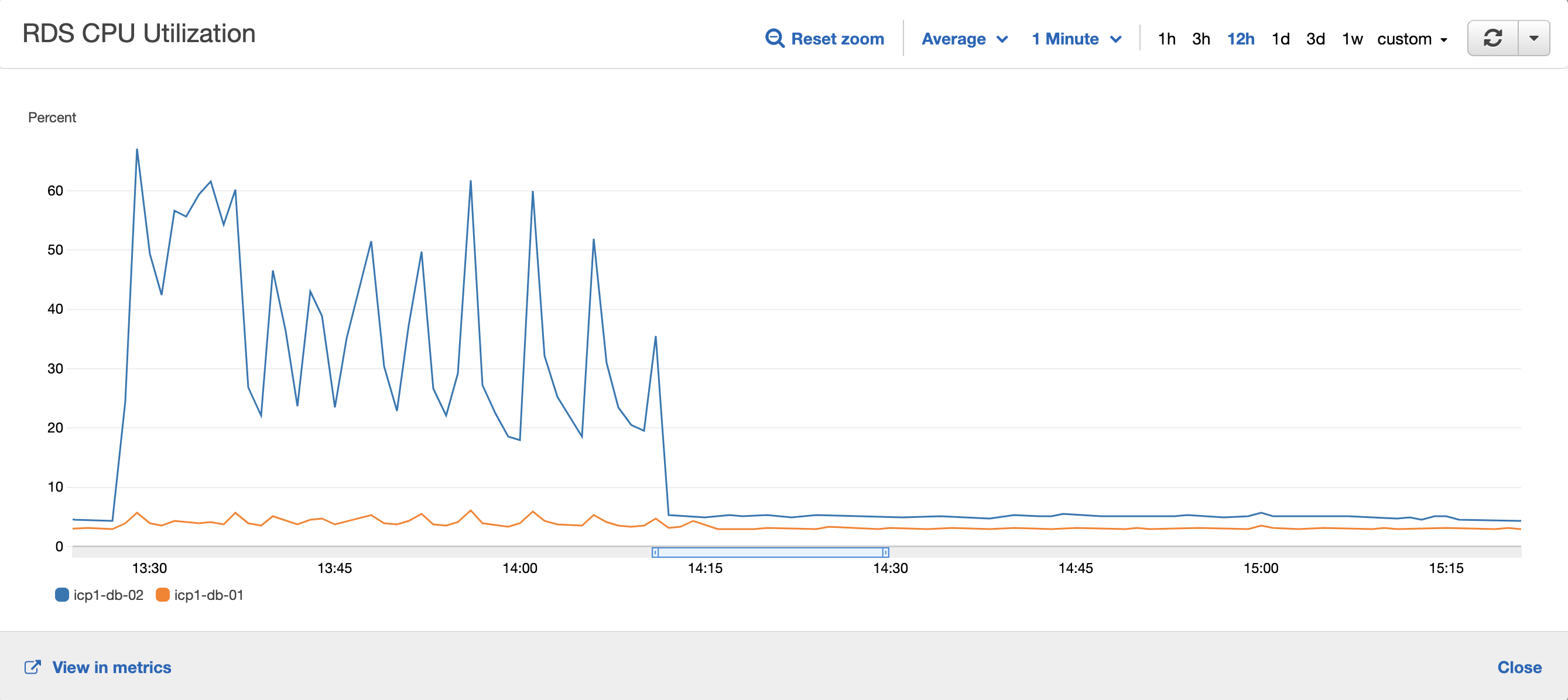
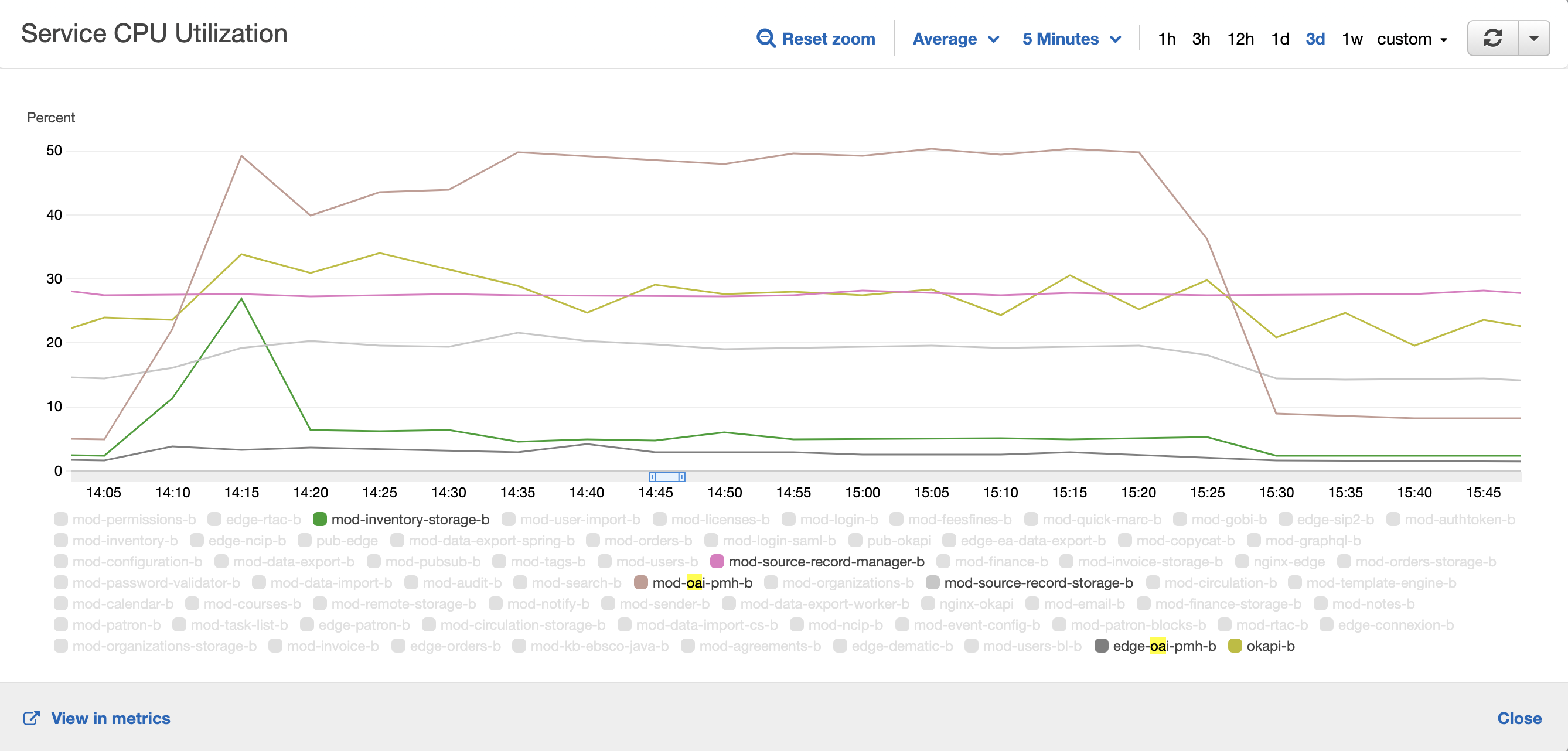
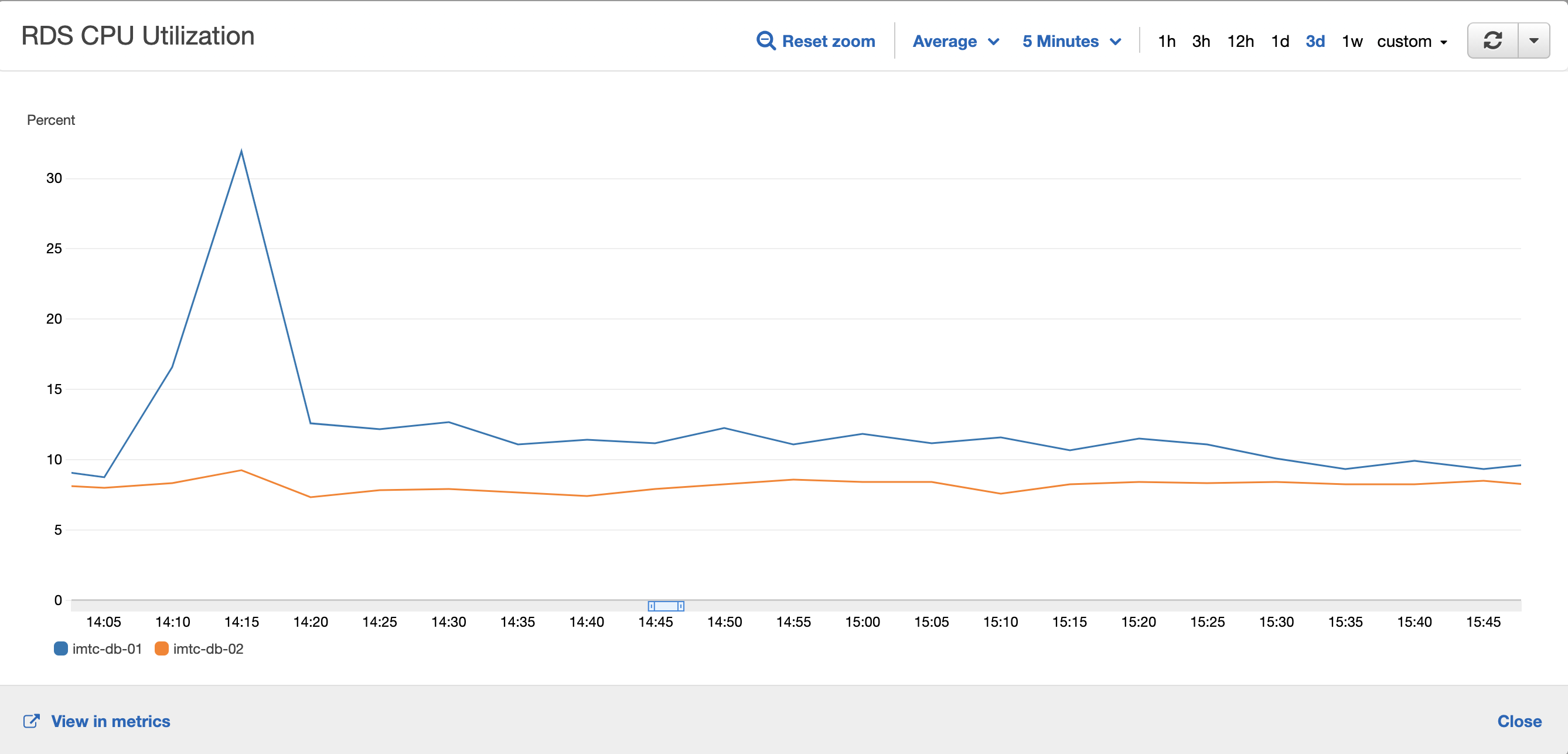
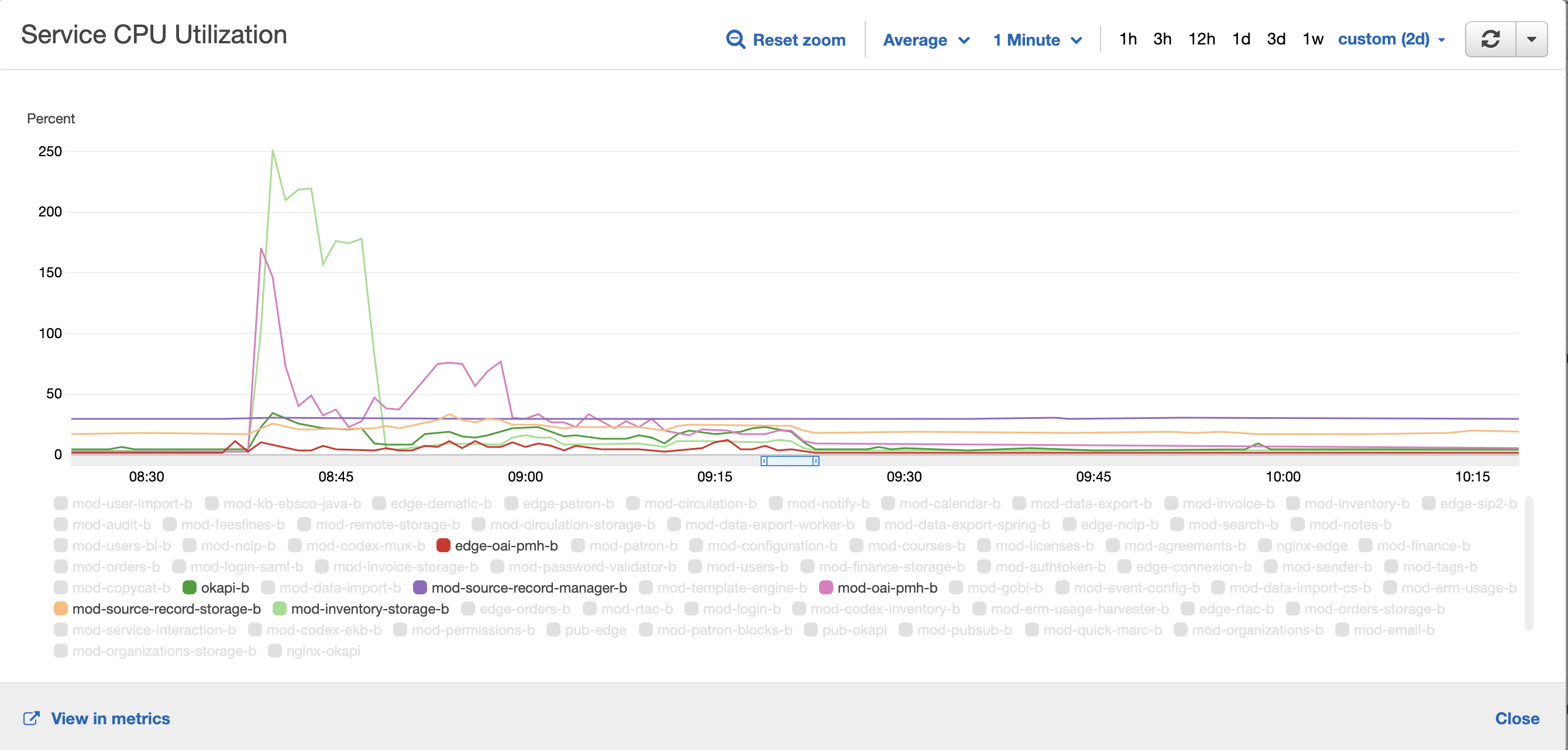
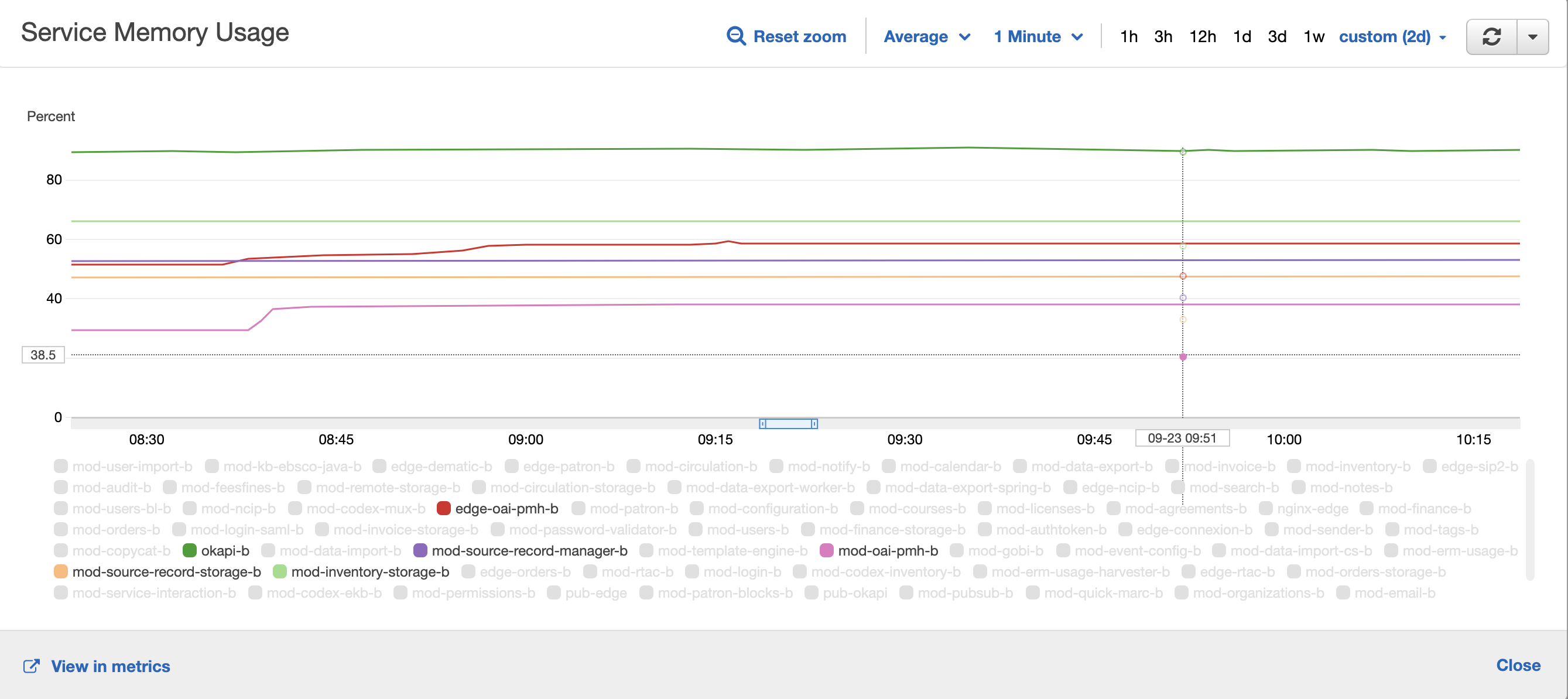
Resource usage
IMTC
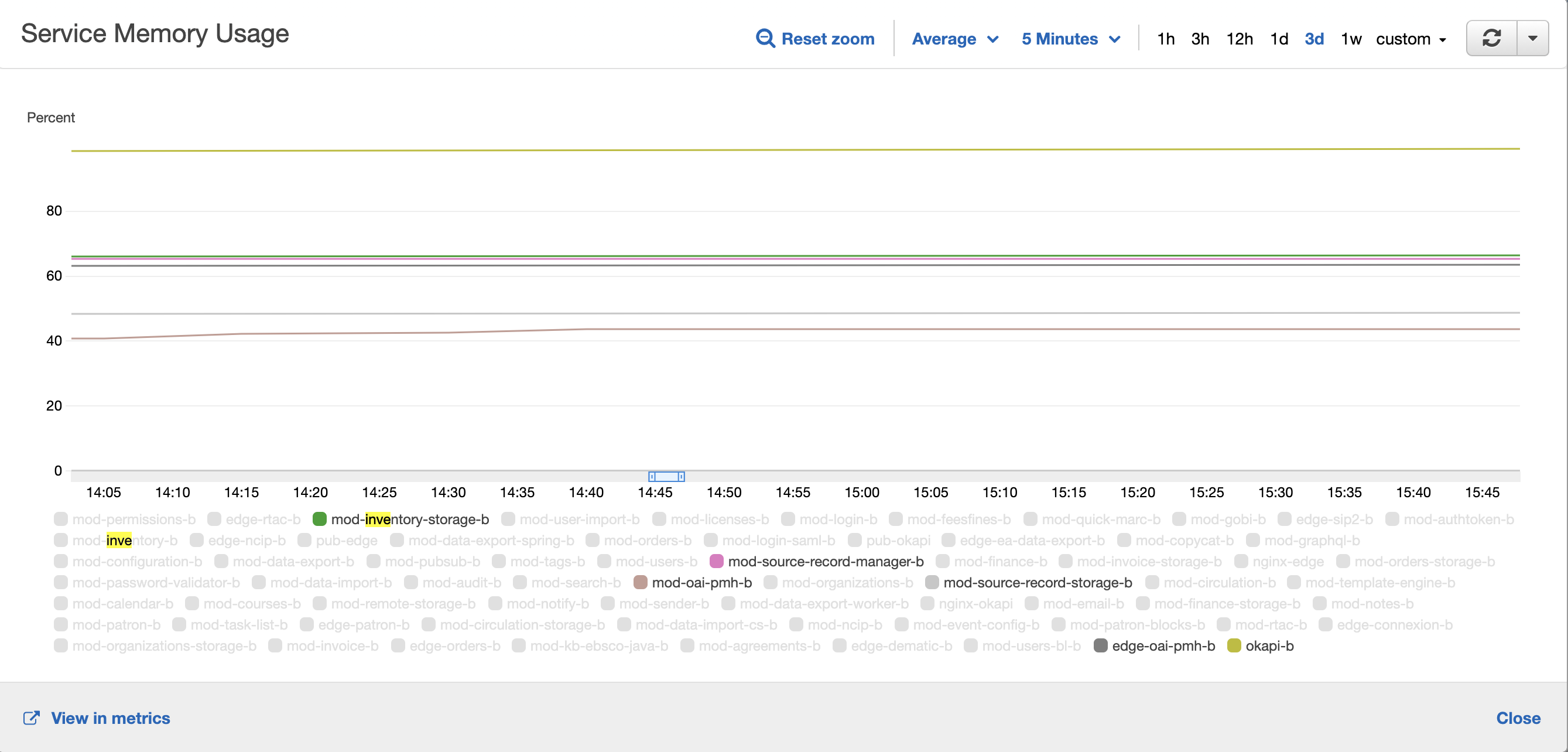
JCP1
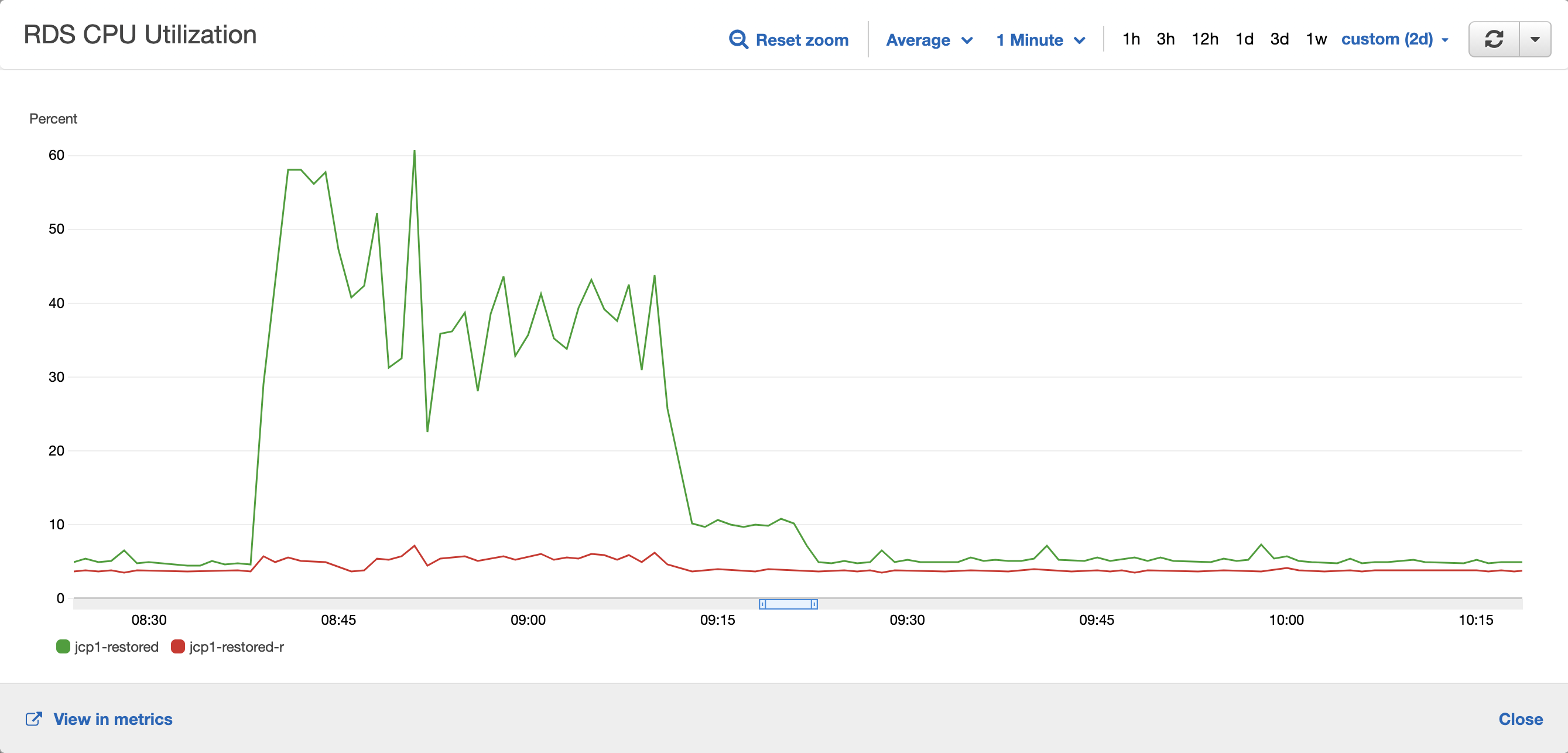
ICP1