MODDATAIMP-361 - Getting issue details... STATUS
Goal and requirements
The goals of importing MARC Authority records into Source Record Storage (SRS) are:
- Create new MARC authority records
- Update/Modify existing MARC authority records using matching/mapping profiles
- Search imported MARC authority records by means of SRS MARC Query API
Requirements
- Supported file extensions/formats: All files with Data type = MARC
- Honor MARC Field protection entries
- Support mapping profiles to populate authority records
- Support match profiles that allow matching MARC authority records
- Support job profiles to execute import requests
- Import actions to support:
- Create record
- Update entire record
- Modify record (not for initial release)
- Delete record (not for initial release)
- When a user imports then
- generate a HRID
- generate UUID
- store imported authority records in SRS
Creation of MARC authority records
Creation of new MARC authority records should be similar to the process of creating new MARC Bib records in the sense that both of these records share the same format which can be accepted by SRM/SRS. Any extensions to the process that customize MARC Bib record creation are done either by external modules (like mod-inventory) or hidden behind general interfaces (like EventProcessor). Having that in mind it can be assumed that MARC Authority records creation should follow the same pattern as for MARC Bib. So let's revise a very high level view of the creation flow.
High level description of existing MARC Bib records creation flow
- SRM receives request to process a batch of MARC records in raw format (Json/Marc/XML)
- entry point:
EventDrivenChunkProcessingServiceImpl - existing job execution entry initialized if necessary and its status is set to
PARSING_IN_PROGRESS - incoming records parsed from raw format and kept in the objects of
Recordtype with other supplemental data
- entry point:
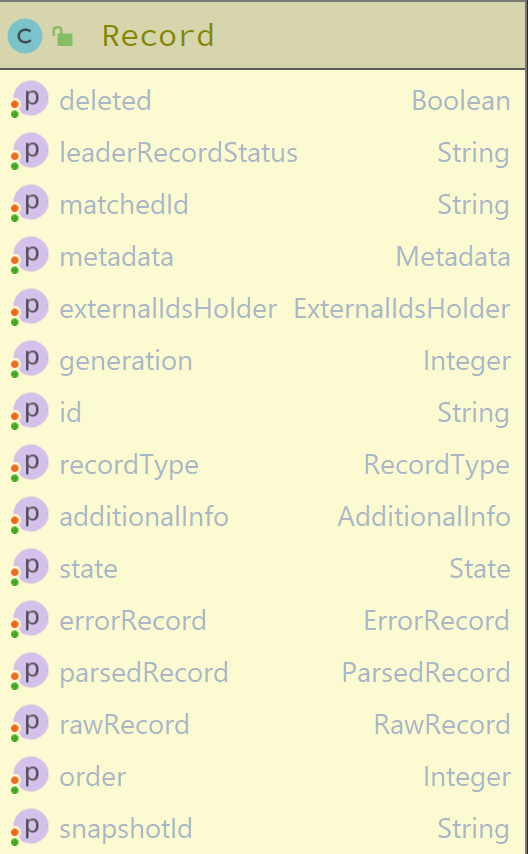
DI_RAW_MARC_BIB_RECORDS_CHUNK_PARSEDevent is sent to notify that raw records have been parsed- journal records created for the parsed records
2. SRS retrieves parsed records from the appropriate event topic and saves them to MARC records database
- entry point:
ParsedMarcChunksKafkaHandler - parsed records transformed into DB representation and saved
- raw records saved
- initial generation created
DI_PARSED_MARC_BIB_RECORDS_CHUNK_SAVEDevent is sent to notify that new records have been saved
- entry point:
3. SRM gets saved records from the event topic and notifies other consumers that the records are created
- entry point:
StoredMarcChunksKafkaHandler DI_SRS_MARC_BIB_RECORD_CREATEDevent is sent for each parsed record with the following payload
- entry point:
context property contains:
- encoded Record object mapped to
MARC_BIBLIOGRAPHICentity type
- encoded Record object mapped to
- mapping rules
- mapping parameters
4. SRS consumes each created record and applies
- entry point:
DataImportKafkaHandler - registered event processors applied if applicable to the record
InstancePostProcessingEventHandlerModifyRecordEventHandlerMarcBibliographicMatchEventHandler
- if all profiles applied to the record
DI_COMPLETEDevent is sent to signal that the import process is finished (in case of errorDI_ERRORevent published)
- entry point:
5. SRM accepts completion event and finalize the process for the record
- entry point:
RecordProcessedEventHandlingServiceImpl - update general job execution progress with the record result
- save journal record if necessary
- update final job execution status if the record is the last one to be imported
- entry point:
Creation flow modification
In general current flow should be applicable to MARC Authority records importing. Some issues have been identified. But the list is not complete and further investigation might reveal another problems. Known limitations are related to implicit use of MARC Bib record type:
- SRM always publishes Data Import Events with Record mapped to MARC Bib type
- Event naming includes MARC Bib type explicitly. There is no other type support inside the naming neither mechanism to identify the required event by record type
SRM always publishes Data Import Events with MARC Bib type
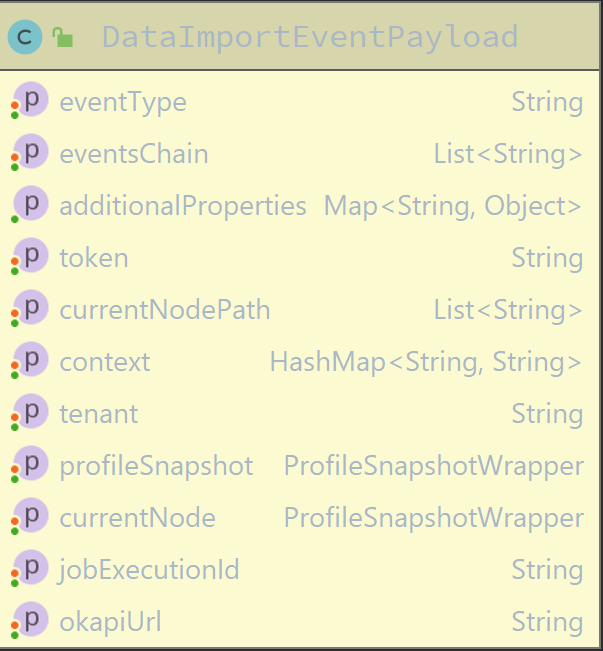
SRM contains class which is used by service to publish record events: RecordsPublishingServiceImpl. This class prepares event payload in the following way:
private DataImportEventPayload prepareEventPayload(Record record, ProfileSnapshotWrapper profileSnapshotWrapper,
JsonObject mappingRules, MappingParameters mappingParameters, OkapiConnectionParams params,
String eventType) {
HashMap<String, String> dataImportEventPayloadContext = new HashMap<>();
dataImportEventPayloadContext.put(MARC_BIBLIOGRAPHIC.value(), Json.encode(record));
dataImportEventPayloadContext.put("MAPPING_RULES", mappingRules.encode());
dataImportEventPayloadContext.put("MAPPING_PARAMS", Json.encode(mappingParameters));
return new DataImportEventPayload()
.withEventType(eventType)
.withProfileSnapshot(profileSnapshotWrapper)
.withCurrentNode(profileSnapshotWrapper.getChildSnapshotWrappers().get(0))
.withJobExecutionId(record.getSnapshotId())
.withContext(dataImportEventPayloadContext)
.withOkapiUrl(params.getOkapiUrl())
.withTenant(params.getTenantId())
.withToken(params.getToken());
}
The code in line #5 encodes Record and places it into the context map with the key = "MARC_BIBLIOGRAPHIC". This is done regardless of the real record type which can be one of the following:
public enum EntityType {
MARC_BIBLIOGRAPHIC("MARC_BIBLIOGRAPHIC"),
MARC_HOLDINGS("MARC_HOLDINGS"),
MARC_AUTHORITY("MARC_AUTHORITY"),
EDIFACT_INVOICE("EDIFACT_INVOICE"),
DELIMITED("DELIMITED"),
INSTANCE("INSTANCE"),
HOLDINGS("HOLDINGS"),
ITEM("ITEM"),
ORDER("ORDER"),
INVOICE("INVOICE"),
STATIC_VALUE("STATIC_VALUE");
private final String value;
}
The enumeration already defines required type for MARC Authority records, it just has to be detected from the record and placed into the payload. Detection mechanism implemented in MarcRecordAnalyzer.java from data-import-utils module. It'll allow to put a record into the context with the appropriate type value as a key.
Event naming includes MARC Bib type only, no support for other types
Data import defines a list of available events in DataImportEventTypes enum:
There are events that are issued upon general purpose actions. Exmples of such events are:
DI_RAW_MARC_BIB_RECORDS_CHUNK_PARSEDorDI_PARSED_MARC_BIB_RECORDS_CHUNK_SAVED
They are different from other events in a sense that they can be applied to MARC records of any type. For instance, parsing of incoming MARC record into common format doesn't depend on the record type. The same is true for MARC record saving in SRS database.
Because of the above it makes sence to generalize some events by removing "_BIB_" part from the name, for instance:
DI_RAW_MARC_BIB_RECORDS_CHUNK_PARSEDbecomesDI_RAW_MARC_RECORDS_CHUNK_PARSEDDI_PARSED_MARC_BIB_RECORDS_CHUNK_SAVEDbecomesDI_PARSED_MARC_RECORDS_CHUNK_SAVED
Once the general flow completes, the process can be customized for particular type of records with specific events that include "_BIB_" or "_AUTH_" or other qualifiers. This separation is supposed to happen after record creation, so the events to notify about a record's been successfully created have to have type qualifier inside:
DI_SRS_MARC_BIB_RECORD_CREATEDDI_SRS_MARC_AUTH_RECORD_CREATED
This should bring more control on record processing customization and limit the number of unwanted executions of the services that are interested in one type of record but not in the other.
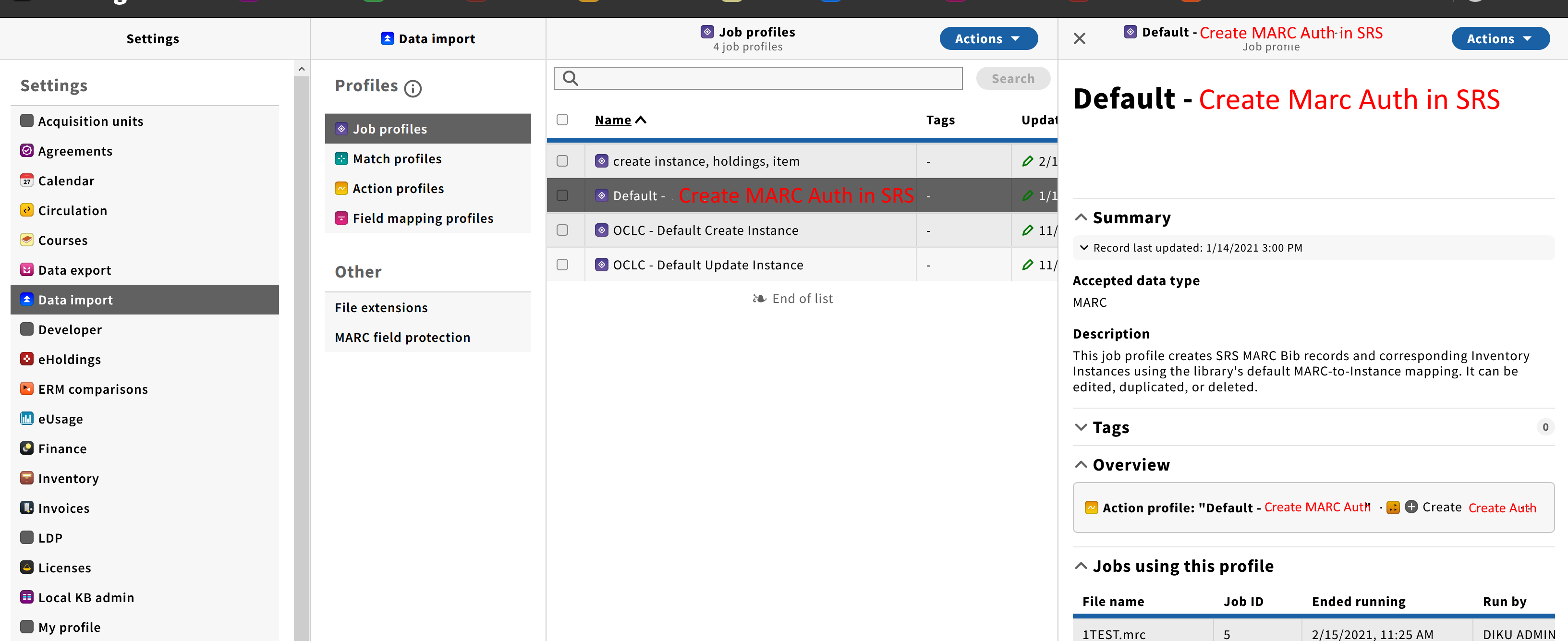
Creation profile
Similar to MARC Bib records there has to be a default data import profile for MARC Authority records. Unlike bibliographic records importing though there is no need to create any additional entities, like inventory records, during authority records import. So the profile could be simplified to job profile which includes single action: Create MARC Authority in SRS.
Mock ups for the default profile:
- Job profile
- Action profile
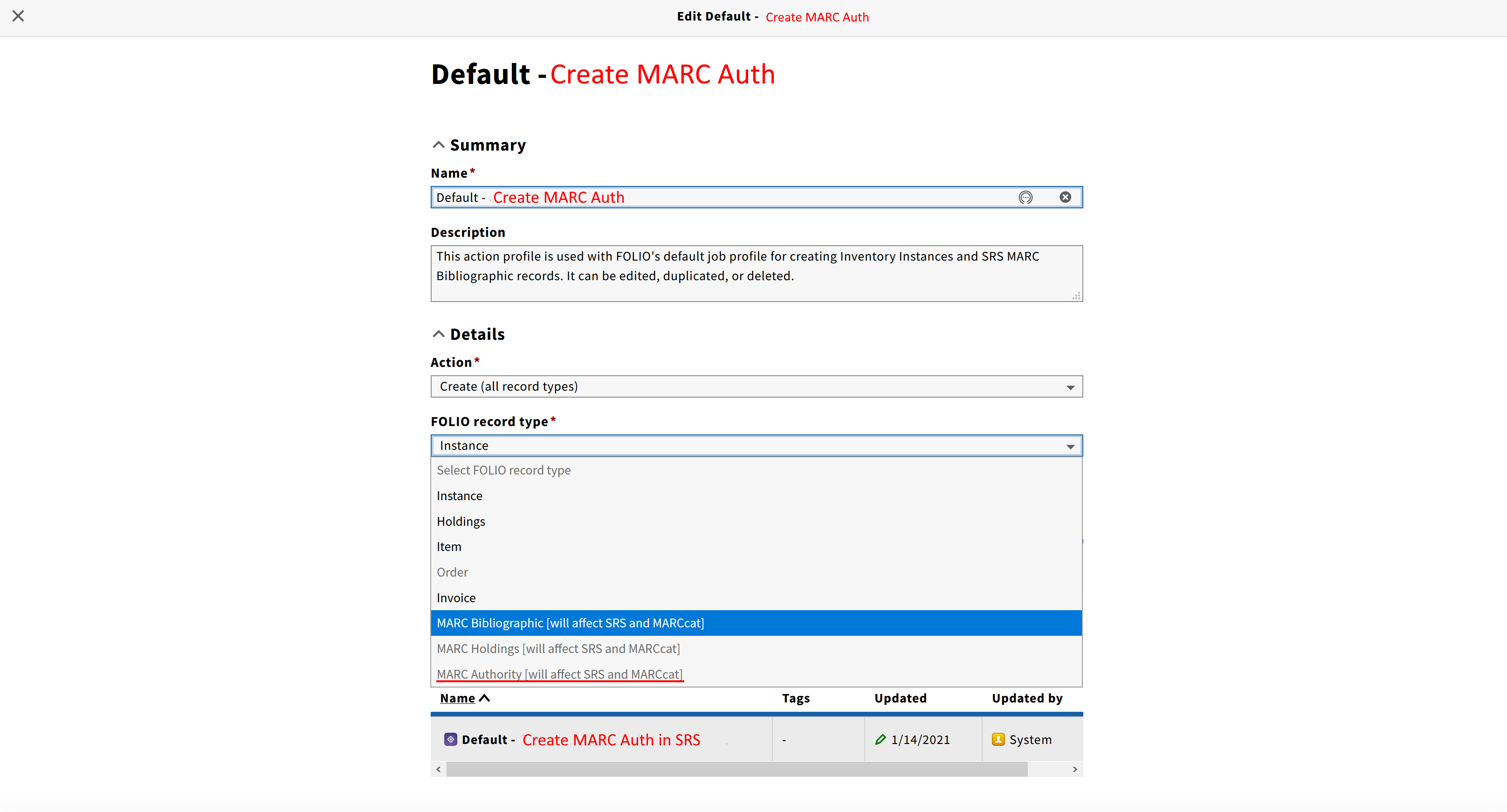
For the reference, default Job/Action profiles for MARC Bib record import:
Open questions:
|
|---|
Generation of HRID
TBD
Uncovered Areas
Below are the business areas that mentioned in the requirements but not covered by this spike:
- Updating MARC Authority records
- existing flow and modifications required to support Authority records
- matching profiles
- mapping rules and parameters
- Searching MARC Authority records with SRS MARC Query API